Author: The looking glass
Recommended reason:
Recommended reason:
"Who am I" is any self-conscious person's self-awareness of himself, and in this self-awareness he becomes the object of his own thinking. Identity is a comprehensive and complex concept that psychologically constitutes the traits, beliefs, personality, appearance and expression of a person or group. How to express the concepts of on-chain identity, digital identity, and network identity, and what kind of identity management system do we need in the decentralized narrative? How is decentralized identity (DID) better than the existing web2 identity system?
We have survived in the isolated island of the web2 world for too long, with privacy leaks, information abuse, and algorithm exploitation. This article attempts to explore how we can build a brand new identity table through distributed identity tables under the leadership of Data sovereignty."I own my data"identity system.
The more one writes about "identity," the more the word becomes an unfathomable term because of its ubiquity. ——Erik Erikson
As Erik Erikson, the psychologist who coined the term "identity crisis," says, I often feel it's true: Identity is a nebulous concept with many connotations, and its meaning is highly dependent on For context, this is no exception in Web3.
In this post, I'll try to address this problem: building a framework—one that views identity in the web as a tool primarily for storing, managing, and retrieving information.
first level title
What's in the name? Three Meanings of "Identity"
When people talk about identity, they usually mean one of three related but distinct scopes: a) a unique identifier, b) an overall view of an entity, or c) a specific context about an entity.
Unique identifiers are crucial in any social setting. Among friends, family members, or small tribes (below Dunbar's threshold of 150 people) who can be assumed to be familiar, a name is a sufficient "identifier". Beyond that, stricter identifiers help make participants "visible" within the wider system. States implement ID cards to administer taxes, conscription, and social programs. The web application has user IDs in the user table, which it uses to track, manage and service its customers.
A holistic view refers to all possible information about a user or other actors. Attempting to attach large amounts of data to a unique identifier can create a rich set of information about a person or entity. The pursuit of this can be seen in Facebook and Google's user databases, India's Aadhaar and China's social credit systems, and customer data platforms like Segment and LiveRamp.
A particular context can be represented as any of many subsets of the overall view. KYC or Identity Verification - a multi-billion dollar industry - is about verifying that someone is the only verifiable identity they claim to be within the national system. Likewise, authentication, anti-fraud, anti-spam, and credit algorithms are specific services that focus on subsets of information in a holistic view.
first level title
Identity: attach information to an identifier
Unique identifiers are necessary but useless by themselves. They are almost always used to jump to some information. This could be names and addresses in state records, documents in a file system, passwords in an application database, or token balances or transaction history on a blockchain. In any case, an identifier is useful because it conveys relevant information.
Many situations require retrieval or verification of specific contexts linked to identifiers. For example, Gitcoin needs an "identity system" to prevent outside attacks on its Grants platform. In practice, they need to map personality evidence (KYC verification, twitter account) to a unique identifier. The more information they have about the individual's unique or fraudulent potential, the better their platform can work.
The holistic view of identity is always incomplete — just as we can never perfectly describe our “true selves” in space, our digital selves will never be completely consistent or comprehensive. But the more data collected around a single (or set of linked) identifiers, the more information we can use for any given context.
The common denominator is: Identity systems create the ability to reliably associate information with unique identifiers. The more reliable an identity system is, the more useful it is and:
more reliable:Available, fault-tolerant, tamper-proof
more flexible:Can handle more types of information
Easier to use:Can be used in more contexts, unifying rather than dispersing information
first level title
Digital identity as a 🔑 of the web
In the most simplified terms, the web runs on hardware, code, and data. Every website you visit has logic and rules written in code, and almost all websites are filled with information encoded in data. This data—whether it's today's news, your friend's tweets, or your latest email draft—must be retrieved accurately and reliably when you arrive at the site. This is done through identifiers.
Just as a unique identifier is useless without the data attached to it, data on the web is not very useful if it cannot be retrieved at the correct time. Unique identifiers, and the routing tables and logic built around them, are used to organize the data that populates it on the network. Who is creating these identifiers? Who is organizing data around them?
image description
Traditional user tables on the application database
Does this identity system meet our criteria above?
reliable:👍🏽 is very reliable but 👎🏽👎🏽 is not auditable and highly vulnerable to hacks and bugs
flexible:👍🏽 Database types can be chained to handle various information, although it can be a bit confusing
Available:👎🏽👎🏽👎🏽 Each application needs its own identifier, the information (and its management) is very fragmented, redundant and inefficient
From a macro perspective, this is a very bad identity system for the web - because it's not one identity system, it's many different identity systems. It fragments information, limiting its value and use to each participant. (This also creates a terrible incentive for hoarding and misusing user data beyond the scope of this article).
first level title
Decentralized Identity: How Web3 Surpasses Web2
Blockchain is a form of distributed ledger technology (DLT), which is basically a shared database. A shared database seems like a good place to put a unified user table, and get rid of the archaic need for each application to create its own identity system.
This is the future vision of decentralized identity and a core pillar of the Web3 vision: every user and builder is in control of their own data, value, relationships and information. In this vision, each user becomes a unified point of discovery for their own data, creating reuse and composability across applications. This creates shared network effects, interoperability, and composite experiences that siled centralized applications cannot compete with.
The original version's vision envisioned a unified user registry (on one DLT) and a standard way for all applications to add information to that registry. Users control their own encrypted sovereign address (or identifier) with which they sign all data to create the trust that data requires in an open environment. We let every app use the same registry (blockchain) and publish data using a standard format (NFT) and in theory we are in identity nirvana - a network that brings the social graph to apps, independent of audiences and communities seamlessly interact with platforms and easily move between new products and services as soon as they become available because they are all interoperable.
However, this vision of decentralized identity - which relies on addresses and NFTs - quickly falls apart in practice. It is too rigid to manage and route data at scale well as an identity system. On our standards:
reliable:👎🏽 Today's blockchains, designed for consensus on scarce financial assets, cannot scale to meet the scale of large amounts of data; nor can they handle off-chain (or partial) updates
flexible:👍🏽👎🏽 Most on-chain ledgers support new data structures and standards, but within the constraints of the consensus system. This limits the use cases and applications of the system
Accessibility:👎🏽 A single registry limits users and applications to a single DLT or blockchain, while we inevitably use different chains and networks
We can learn from the flaws of the original cryptographic identity systems to understand what is needed for a more reliable decentralized identity system. Clearly, a single registry (index), identifier standard, or data structure standard is always too rigid.
first level title
How Web3 will handle user tables
In order to manage data, we need a protocol to easily store, discover, and route information about identifiers. For Web3 to deliver on its promise, this routing table should a) be unified, not isolated by application or any other boundary, and b) be sovereign, delegating control of the data directly to each identifier.
This suggests a simple design: each identifier maintains a table containing its own data. Taken together, these identity-centric user tables form the Internet's distributed user table. This distributed user table is not an actual table, but a virtual table, which is produced by several components corresponding to the parts of the traditional user table:
Identifier:Decentralized identifiers should not be entries in the application database, but should be provably unique and cryptographically controlled. Accessibility requires the acceptance of multiple forms of identifiers across various networks - similar to the DID standard for decentralized identifiers.
data structure:index:
index:image description
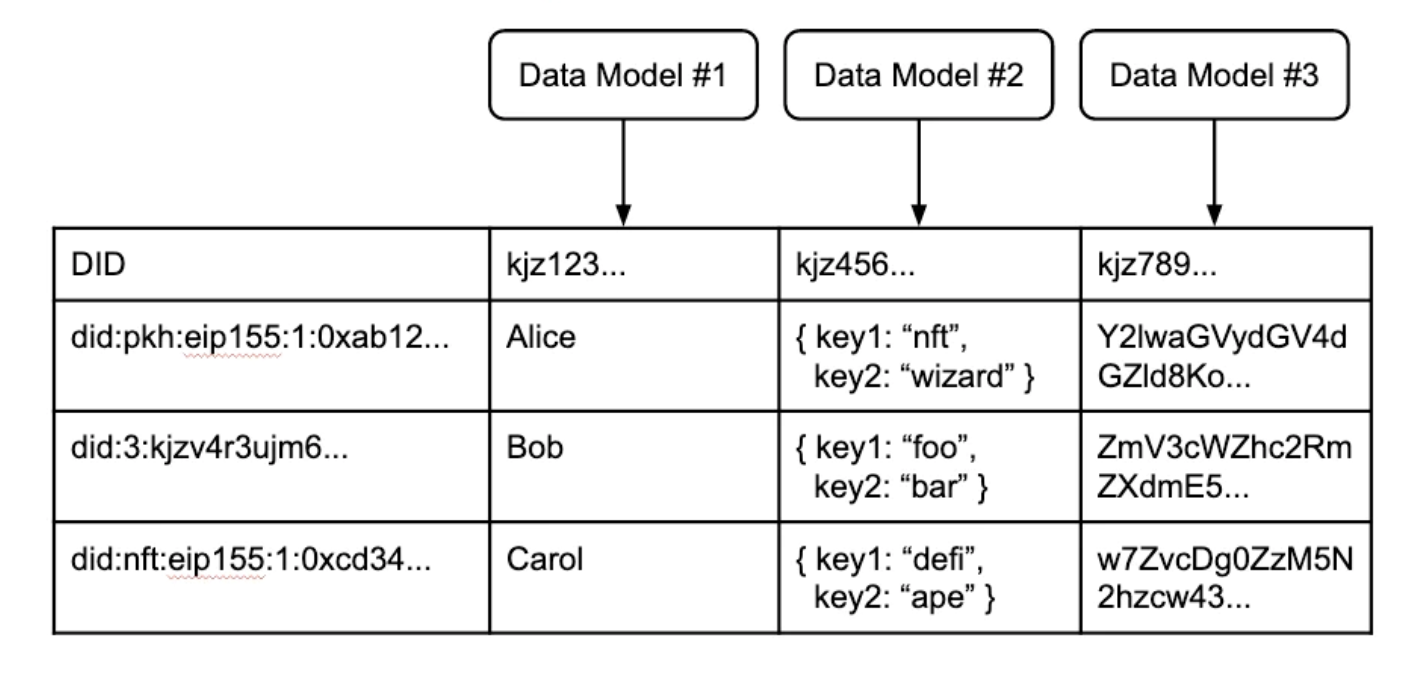
A distributed virtual user table with various DIDs from different networks, a developer-defined data model, and records associated with each
first level title
Build with Distributed User Table
How does this identity system based on DIDs and data models and distributed user tables meet our criteria?
reliable:👍🏽👍🏽 Runs on public collections of networks that anyone can participate in, including partitioned or local networks
flexible:👍🏽👍🏽 Works with any data structure a developer can define
Availability:👍🏽👍🏽 Works with any open network and unique identifier
The system also has a number of additional properties that make for a highly flexible and reliable identity system. include:
Kana first:There is no need to create an account or verify to get started, the user (or other entity) just needs to carry a cryptographic key pair and start accumulating information around it
can generate:Information accumulates over time, creating an emerging holistic identity
Composable:Discover and share information across contexts without pre-defined integration or portability standards
separable and selective: Information sets may be encrypted or obfuscated, or separated across multiple identifiers, or otherwise split at the controller's preference
If "identity systems are capable of reliably associating information with unique identifiers", as stated earlier, we need an internet identity system that establishes minimal protocols for managing and routing to trusted data, leaving everything else to ingenuity and application developer diversity.
We want to avoid siled systems—including specific applications, registries, or blockchains—and maximize flexibility in data types. We need an easy-to-use system that allows us to build applications with rich forms of data, associate those data with appropriate identifiers, and derive maximum utility from our identities and collective information.
Translator's note:
Translator's note:
The future of web3 and Metaverse blurs the boundary between the off-chain world and the on-chain space. Therefore, for the construction of the identity management system, how to establish the mapping relationship between off-chain identities and on-chain data is the digital life space for developing a new social system. The must-do homework and the foundation of a foothold.
An isolated identity system is an obstacle to a seamless Dapp experience in the future. Building a distributed user table is conducive to breaking through existing application islands. How to find a balance between flexibility, openness, and reliability in the DID system? The author recommends Ceramic and other infrastructure, we will make project analysis in related articles later.
H.Forest Ventures will do its best to fully understand the relevant information for each shared content. If you have any thoughts on the content of this article, please contact the H.Forest Ventures team.
Effective communication is everything.