Original author: Zhiyong Fang
"How do you eat an elephant? One bite at a time."
In recent years, machine learning models have achieved leaps and bounds at an astonishing rate. As the capabilities of models have increased, their complexity has also increased simultaneously - today's advanced models often contain millions or even billions of parameters. To cope with this scale challenge, a variety of zero-knowledge proof systems have emerged, which always strive to achieve a dynamic balance between proof time, verification time and proof size.
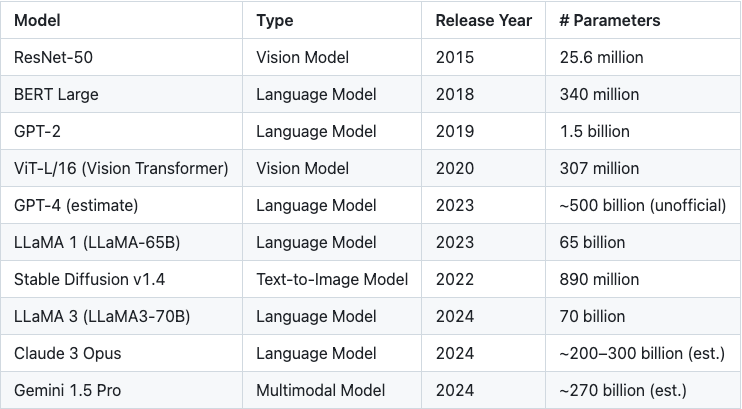
Table 1: Exponential growth in model parameter size
Although most of the current work in the field of zero-knowledge proofs focuses on optimizing the proof system itself, a key dimension is often overlooked: how to properly split large-scale models into smaller, more manageable sub-modules for proof. You may ask, why is this so important?
Let's explain in detail:
The number of parameters in modern machine learning models is often in the billions, which already occupies a very high amount of memory resources even without any cryptographic processing. In the context of zero-knowledge proof (ZKP), this challenge is further magnified.
Each floating-point parameter must be converted to an element in the algebraic field, and this conversion process itself will increase the memory usage by about 5 to 10 times. In addition, in order to accurately simulate floating-point operations in the algebraic field, additional operation overhead must be introduced, which is usually about 5 times.
In general, the overall memory requirement of the model may increase to 25 to 50 times the original size. For example, a model with 1 billion 32-bit floating-point parameters may require 100 to 200 GB of memory just to store the converted parameters. Considering the overhead of intermediate calculation values and the proof system itself, the overall memory usage easily exceeds the TB level.
Current mainstream proof systems, such as Groth 16 and Plonk, usually assume that all relevant data can be loaded into memory at the same time in unoptimized implementations. Although this assumption is technically feasible, it is extremely challenging under actual hardware conditions and greatly limits the available proof computing resources.
Polyhedra’s solution: zkCuda
What is zkCuda?
As we stated in the zkCUDA Technical Documentation :
Polyhedra's zkCUDA is a zero-knowledge computing environment for high-performance circuit development, designed to improve proof generation efficiency. Without sacrificing circuit expressiveness, zkCUDA can fully utilize the underlying prover and hardware parallel capabilities to achieve fast ZK proof generation.
The zkCUDA language is highly similar to CUDA in syntax and semantics, and is very friendly to developers who already have CUDA experience. Its underlying implementation is in Rust, ensuring both security and performance.
With zkCUDA, developers can:
Quickly build high-performance ZK circuits;
Efficiently schedule and utilize distributed hardware resources, such as GPUs or cluster environments that support MPI, to achieve large-scale parallel computing.
Why zkCUDA?
zkCuda is a high-performance zero-knowledge computing framework inspired by GPU computing. It can split large-scale machine learning models into smaller and more manageable computing units (kernels) and achieve efficient control through a front-end language similar to CUDA. This design brings the following key advantages:
1. Selection of a proof system for exact matching
zkCUDA supports fine-grained analysis of each computing kernel and matches it with the most suitable zero-knowledge proof system. For example:
For highly parallel computing tasks, protocols such as GKR that are good at handling structured parallelism can be used;
For smaller or irregularly structured tasks, it is more appropriate to use a proof system such as Groth 16 that has low overhead in compact computing scenarios.
By customizing the backend selection, zkCUDA can maximize the performance advantages of various ZK protocols.
2. Smarter resource scheduling and parallel optimization
Different proof kernels have significantly different resource requirements for CPU, memory, and I/O. zkCUDA can accurately assess the resource consumption of each task and schedule it intelligently to maximize overall throughput.
More importantly, zkCUDA supports task distribution among heterogeneous computing platforms—including CPUs, GPUs, and FPGAs—to achieve optimal utilization of hardware resources and significantly improve system-level performance.
zkCuda is a natural fit for the GKR protocol
Although zkCuda is designed as a general computing framework compatible with a variety of zero-knowledge proof systems, it has a natural high degree of architectural compatibility with the GKR (Goldwasser-Kalai-Rothblum) protocol.
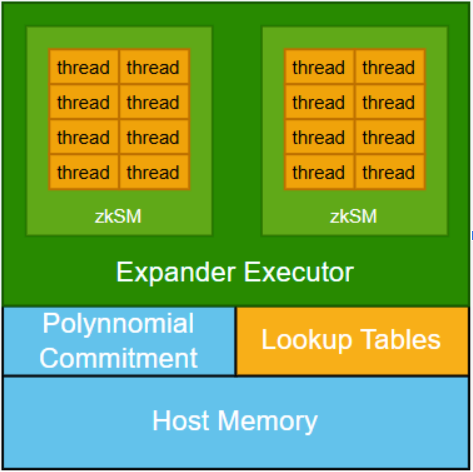
In terms of architectural design, zkCUDA introduces a polynomial commitment mechanism to connect the various sub-computing kernels to ensure that all sub-computing runs based on consistent shared data. This mechanism is crucial to maintaining system integrity, but it also brings significant computing costs.
In contrast, the GKR protocol provides a more efficient alternative path. Unlike traditional zero-knowledge systems that require each kernel to fully prove its internal constraints, GKR allows the verification of computational correctness to be recursively traced back from the kernel output to the input. This mechanism allows correctness to be transferred across kernels instead of fully expanding verification in each module. Its core idea is similar to gradient backpropagation in machine learning, tracking and transmitting correctness claims through computational graphs.
Although merging such "proof gradients" in multiple paths brings some complexity, it is this mechanism that forms the basis for the deep collaboration between zkCUDA and GKR. By aligning the structural characteristics of the machine learning training process, zkCUDA is expected to achieve tighter system integration and more efficient zero-knowledge proof generation in large model scenarios.
Preliminary results and future directions
We have completed the initial development of the zkCuda framework and have successfully tested it in multiple scenarios, including cryptographic hash functions such as Keccak and SHA-256, as well as small-scale machine learning models.
Looking ahead, we hope to further introduce a series of mature engineering technologies in modern machine learning training, such as memory-efficient scheduling and graph-level optimization. We believe that integrating these strategies into the zero-knowledge proof generation process will greatly improve the performance boundary and adaptation flexibility of the system.
This is just a starting point. zkCuda will continue to move towards a universal proof framework that is efficient, highly scalable, and highly adaptable.