ChatGPT has driven the global trend of large-scale models, causing "model wars" among internet companies, and even leading to "overfitting": each company's released model is bigger than the previous one, with parameter sizes becoming a promotional gimmick, reaching billions, trillions, or even more.
However, some argue that this situation is not a sustainable development approach. OpenAI founder Sam Altman stated that the development cost of GPT-4 exceeds $100 million. A report by Analytics India Magazine shows that OpenAI spends approximately $700,000 per day to operate its AI service, ChatGPT. Additionally, LLM raises concerns about power consumption. According to a Google report, training PaLM consumes about 3.4 kWh in approximately two months, which is equivalent to the annual energy consumption of around 300 American households.
Therefore, as model sizes continue to grow, Julien Simon, Chief Evangelist at HuggingFace, suggests that "Smaller is better." In fact, after reaching a certain parameter size, increasing parameters often does not significantly improve model performance. Considering practicality and cost-effectiveness, "model slimming" becomes a necessary choice. Compared to the diminishing marginal benefits brought by huge parameter sizes, the enormous resource consumption cost is often not worthwhile. Moreover, large models can create many deployment issues, such as the inability to deploy on edge devices, only being able to provide services to users in the cloud form. However, many times, we need to deploy models on edge nodes to provide personalized services to users.
If we want to continue improving AI models, developers will need to address how to achieve higher performance with fewer resources. Whether in academia or industry, model compression has always been a hot field, and there are currently many technologies working on it. This article briefly introduces four common model compression techniques: quantization, pruning, parameter sharing, and knowledge distillation, aiming to provide an intuitive understanding of model compression methods.
1. Theoretical Basis of Model Slimming: "Marginal Diminishing Returns" of Parameter Size
If we consider a model as a "bucket," data as "apples," and the information contained within the data as "apple juice," then the process of training large models can be understood as the process of pouring apple juice into the bucket. The more apples, the more apple juice, and we need a bigger bucket to hold the apple juice. The emergence of large models is like creating a larger bucket, which enables us to have a greater capacity to hold enough apple juice.
If there are too many apples and too much apple juice, it will cause "overflow", which means that the model is too small to learn all the knowledge in the dataset. We call this situation "underfitting", which means that the model cannot learn the true data distribution. If there are too few apples and too little apple juice, it will cause "not being full". If we try to "squeeze juice" and fill the bucket by increasing the duration of model training, it will increase impurities in the juice and result in a decrease in model performance. We call this situation "overfitting", which means that the model overly learns the data and reduces its generality. Therefore, matching the model size with the data size is very important.
Although the above example is vivid, it can easily create a misunderstanding: a one-liter bucket can hold one liter of apple juice, and a two-liter bucket can hold two liters (as in ①). However, in reality, the amount of information that parameters can contain does not increase linearly with the parameter size, but tends to exhibit a "marginal diminishing" growth (as in ②③).
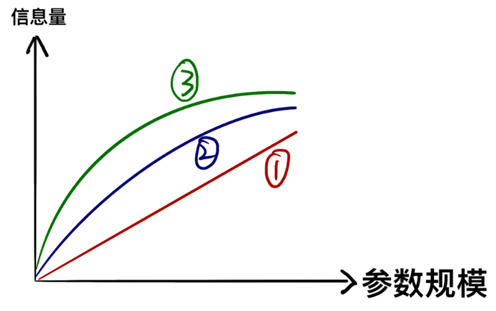
In other words, the extraordinary abilities demonstrated by large models are because they have learned a lot of "detail-oriented knowledge" and have a large number of parameters dedicated to "detail-oriented knowledge". When we have already learned most of the knowledge in the data, continuing to learn more detailed knowledge requires adding more parameters. If we are willing to sacrifice some accuracy, ignore some detailed information, or prune the parameters responsible for identifying detailed information, we can greatly reduce the parameter size, which is the theoretical basis and core idea of model slimming in the academic and industrial fields.
2. Quantization - The most "direct and simple" method of slimming
In computers, the higher the precision of a number, the larger the storage space required. If the precision of a model's parameters is very high (intuitively, it means there are many decimal places), then we can directly reduce the precision to achieve model compression. This is the core idea of quantization. Generally, a model's parameters are represented in 32-bit format. If we agree to reduce the precision of the model to 8 bits, we can reduce the storage space by 75%.
The theoretical basis of this method is a consensus among quantization proponents: complex and high-precision models are necessary during training because we need to capture small gradient changes during optimization. However, it is not necessary during inference. Therefore, quantization can reduce the model's storage space without significantly reducing its inference capability.
3. Pruning - "Surgical removal" of parameters
Large models have a huge size, complex structure, and contain a large number of parameters and structures that have minimal or no effect. If we can accurately identify and remove these useless parts, we can reduce the model's size while ensuring its functionality.
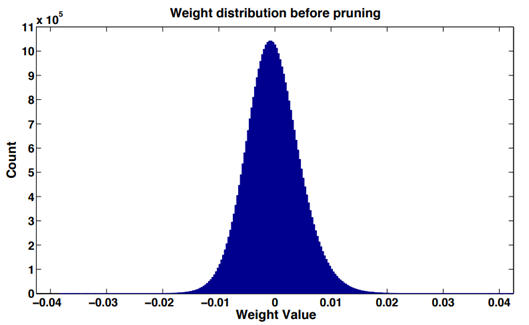
In most neural networks, it is found that the weight values of the network layers (convolutional layers or fully connected layers) approximate a normal distribution or a mixture of multiple normal distributions. There are relatively more weights close to 0, which is called "weight sparsity".
The absolute value of weight values can be seen as a measure of importance. The larger the weight values, the greater the contribution to the model output. Conversely, smaller weight values are less important and have a smaller impact on the model accuracy when removed.
At the same time, there are a large number of neurons in deep networks that are difficult to activate. In the paper "Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures," it was found through some simple statistics that many neurons in the CNN have very low activation regardless of the input image data. The authors believe that zero neurons are likely to be redundant and can be removed without affecting the overall accuracy of the network. This is known as "activation sparsity".
Therefore, based on the characteristics of neural networks mentioned above, we can optimize pruning for different structures to reduce the model size.
4. Parameter Sharing - Finding Small Alternatives for Complex Models
A neural network is a fitting of real data distribution and is essentially a function. If we can find a function with the same performance but smaller parameter size that produces similar outputs for the same inputs, we naturally reduce the parameter size.
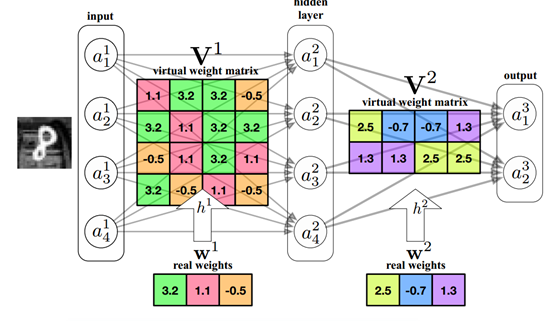
In the field of technology, we often use PCA algorithm for dimensionality reduction to find mappings of high-dimensional arrays to low-dimensional spaces. If we can find a low-dimensional mapping of the model parameter matrix, we can reduce the parameter quantity while ensuring performance.
Currently, there are various methods for parameter sharing, such as weight clustering using K-means, random categorization using hash methods, and processing of weight values within the same group.
5. Knowledge Distillation - Students Replacing Teachers
Since the large model contains a large amount of knowledge, can we "teach" a small model with the large model's abilities? This is the core idea of knowledge distillation.
The large model that we already have is called the Teacher model. At this point, we can use the Teacher model to supervise the training of the Student model, enabling it to learn the knowledge of the Teacher model.
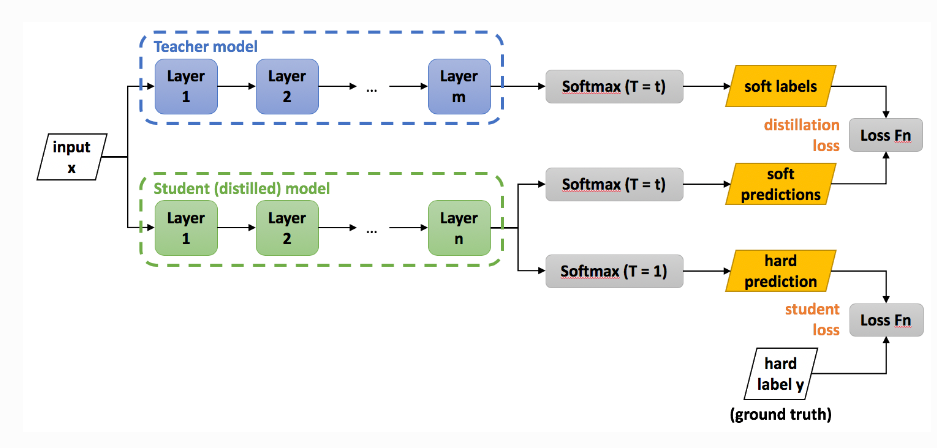
The first three methods more or less change the parameters or structure of the original model, while knowledge distillation is equivalent to retraining a smaller model. Therefore, compared to other methods, it can better preserve the functionality of the original model, but there is a loss in precision.
Conclusion
There is no unified method for model compression. For different models, various compression methods are generally attempted to achieve a balance between size and accuracy. Nowadays, the large models we use are deployed in the cloud, and we only have the right to access rather than ownership. After all, it is not possible to store such large models locally. "Everyone has a large model" seems like an unattainable dream. However, looking back at history, when computers were just born in the 1940s, people saw the huge and power-consuming "machine beasts," and no one would have guessed that it would become a daily tool for everyone decades later. Similarly, with the progress of model compression technology, the optimization of model structures, and the leap in hardware performance, we also look forward to the future where large models are no longer "large" but become personal tools that everyone can have.
References:
https://blog.csdn.net/shentanyue/article/details/83539359
https://zhuanlan.zhihu.com/p/102038521
https://arxiv.org/abs/1607.03250
https://arxiv.org/abs/1806.09228
https://arxiv.org/abs/1504.04788
Copyright Notice: If you need to reprint, please add WeChat Assistant for communication. Unauthorized reprinting or plagiarism will be subject to legal liability.
Disclaimer: The market carries risks, and investment needs to be cautious. Readers should strictly comply with local laws and regulations when considering any opinions, viewpoints, or conclusions in this article. The above content does not constitute any investment advice.