Original: A Singular Trajectory
In 1999, Ray Kurzweil made the following prediction:
In 2009, computers will be tablets or smaller devices with high-quality but traditional displays;
In 2019, computers will be "essentially invisible", with most images projected directly into the retina;
In 2029, computers will communicate via direct neural pathways.
Looking at the development of artificial intelligence, robotics and manufacturing in the past 20 years, especially the recent progress of AIGC, there are some indicators that the development of technology is accelerating towards the singularity.
technological singularity
Singularity originally meant "singularity, prominence, and rarity", and these meanings were gradually extended to the natural sciences, first applied to the field of mathematics, and later extended to the fields of physics and astronomy. Different versions of the "technological singularity" predictions followed.

Technological Singularity "Version 1.0":
In 1958, the concept of "technological singularity" was first proposed by Polish mathematician Stanisław Marcin Ulam: "The acceleration of technological iteration and the change of human life style seem to change the course of our history. brought to an important 'singularity' after which nothing as we know it will continue", and the world will be turned upside down.
Technological Singularity "Version 2.0":
In 1993, computer scientist and science fiction writer Vernor Vinge wrote in his article "The Coming Technology Singularity" that the arrival of the "Technological Singularity" will mark the arrival of the human The end of an era, and superintelligence is a prerequisite for the emergence of a "technological singularity," as new superintelligences will continue to upgrade themselves and make technological progress at an incredible rate.
Technological Singularity "Version 3.0":
In 2005, Ray Kurzweil, the founder and president of Singularity University and Google's technical director, readjusted the concept of "technical singularity" in his book "The Singularity Is Near" , is also closer to the concept we are familiar with, and at the time predicted that the technological singularity would appear in 2045. He believes that "technological singularity" refers to the irreversible changes that rapid and far-reaching technological changes will cause to human life in the future, mainly referring to the rapid development of artificial intelligence. The singularity will allow us to transcend the limitations of biological bodies and brains, and in the future there will be no distinction between humans and machines.
Technological Singularity "Version 4.0":
In 2013, Anders Sandberg, a senior researcher at the Institute for the Future of Humanity at the University of Oxford, expanded the scope of the "technological singularity". Such technological development and changes can be called "technical singularity".
GPT users, dreaming of a companion?
On November 30, 2022, OpenAI released ChatGPT, a conversational interface and large-scale language model. For many, this is a revolutionary moment. Its output is stunning, it saves time and the answers are convincingly true (when OpenAI thinks it is safe to answer).

It's remarkable that you can get an imperfect but effective answer with LLM today in seconds that would have taken minutes of deliberation by domain experts and hours of debate in online forums.
Chatbots have always been the companionship people crave. The motivation behind the Turing test may be wanting a chatbot that doesn't break immersion.
What remains to be tested is whether humans, as social animals, can be augmented with digital brains. We hunt together, we farm together, and society, which can now be described as a vast buffer zone of managers and operators of industrial-scale machines, is more social than ever.
Humans optimize the path of least resistance, choosing to replicate or “Google” the different knowledge they may have acquired through critical thinking and repeated failure. The advent of ChatGPT: Students may use LLM to write papers for them, get good grades. Stack Overflow might be Sybil-attacked for personal gain, and the audience (programmers) might somehow obey the symphony of deepfakes. Script kiddies may indicate that ChatGPT is malware. Is the mainstream use of LLM crippling our ability to be productive, especially in terms of sound, effective and divergent thinking?
The last puppeteer before the singularity
The most profound impact AI can have is in the culture of human capital allocation. A recent opinion nicely describes the reaction to ChatGPT:
The happiest are those who are stunned to discover that the machine is clearly up to the task of writing.
So far, everything is as expected. If you look back at history, people often overestimate the short-term impact of new communication technologies and severely underestimate their long-term impact. The same goes for print, film, radio, television and the Internet.
In trying to understand the impact of AI, we try to isolate the short-term disruption to speculate on the mid- and long-term consequences.
Having said that, perhaps a good way to describe this rally is through market dynamics. AI assistants transform the scarcity of content creation, thereby becoming somewhat of a market maker. Every time a proverbial "genie" leaves the "bottle," consumers gain asymmetrically by repricing the market and phasing out suboptimal suppliers. In turn, suppliers of AI-based production amassed more capital over time.
One could argue that there is an oligopoly of companies that can afford to crawl the entire internet to generate training datasets. Probably only a limited number of SaaS can afford to consume such resources to generate novel ML models. If ML-based commerce becomes sufficiently unstable, fewer people may be able to achieve and maintain PMF. In the past we have been duped by psychological tactics like HAL 9000, Skynet and Butlerian Jihad.
Many companies and intelligent agents collaborate on scarcity in the AI economy. How likely is it that our current capitalist society will produce a technocrat without negative feedback that can phase out socioeconomic classes, fundamental principles like human/property rights, or accelerate some form of mass destruction?
It might sound cliché, but there are upcoming inflection points to watch out for that will have a fundamental impact on how society works. A year from now, someone might be writing quick legislation or tulip mania about a particular AI-dependent product. In 5-10 years there will be a liquidation of the sole proprietorship economy, existing forms of government, and individual autonomy/consumption. The “Megacorp” model may remain dominant throughout the disruption process, and we may find ourselves in a “cyber state,” or something more Orwellian. All because computers (obtained by whatever means) will compile our collective use of natural language to encompass many of the operational and economic functions of society today. Whatever the timeline, this will be a clear inflection point well before the "Singularity."
Method and Technology
image description
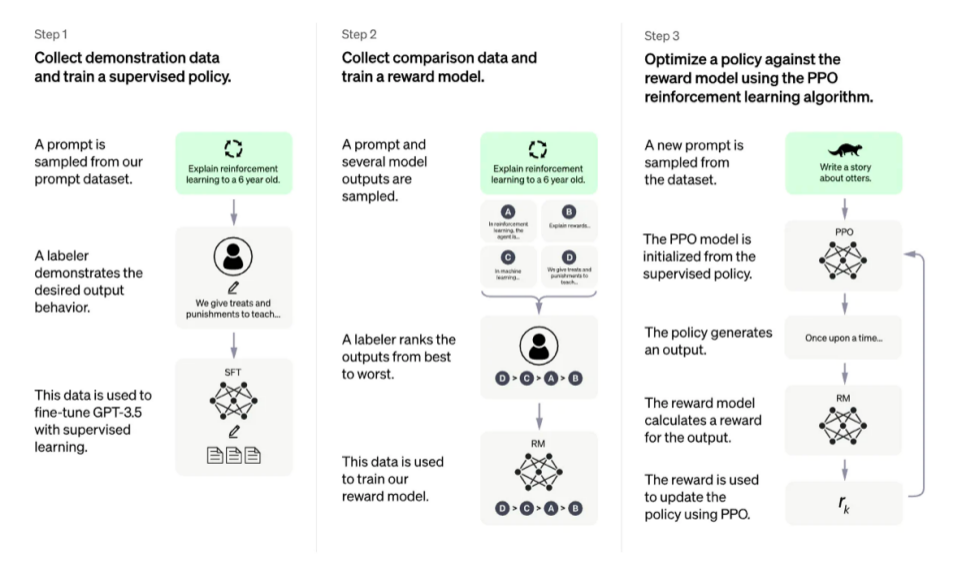
OpenAI's RLHF diagram
However, there are challenges in "perfecting" NLP.
While these technologies are extremely promising and impactful, and have attracted the attention of the largest research labs in artificial intelligence, there are clear limitations. These models can output harmful or actually inaccurate text without uncertainty. This imperfection represents a long-standing challenge and drive for RLHF—operating in an inherently human problem domain means there is never a clear finish line to cross for a model to be marked as complete.
When deploying systems using RLHF, collecting human preference data is expensive due to mandatory and deliberate human factors. RLHF performance is only as good as the quality of its human annotations, which come in two varieties: human-generated text, such as fine-tuning the inception LM in InstructGPT, and human-preferred labels between model outputs.
Generating well-written human text to answer specific prompts is prohibitively expensive, as it often requires hiring part-time people (rather than being able to rely on product users or crowdsourcing). Thankfully, the data size (~50 k labeled preference samples) used to train reward models for most RLHF applications is not that expensive. However, it still costs more than an academic lab might afford.
Currently, there is only one large-scale dataset for RLHF based on general language models (from Anthropic) and several smaller task-specific datasets (such as the summary data from OpenAI). The RLHF data challenge is annotator bias. Several human annotators may disagree, leading to some potential variance in the training data.
RLHF can be applied to machine learning beyond natural language processing (NLP). For example, Deepmind explored its use for multimodal agents. The same challenge applies in this case:
Scalable reinforcement learning (RL) relies on precise reward functions that are cheap to query. When RL can be applied, it has achieved great success, creating AIs that can match the extremes of the human talent distribution (Silver et al., 2016; Vinyals et al., 2019). However, this reward function is not well known for many open-ended behaviors that people regularly engage in. For example, consider an everyday interaction asking someone to "hold a mug near you". For a reward model to be able to adequately evaluate such interactions, it needs to be robust to the many ways in which a request can be made in natural language and the many ways in which it can be fulfilled (or not), while being robust to irrelevant variables of variation (cup's color) and the inherent ambiguity of language (what is "close"?) insensitivity.
Therefore, to instill broader expert-level capabilities through RL, we need a way to generate precise, queryable reward functions that respect the complexity, variability, and ambiguity of human behavior. Instead of programming reward functions, one option is to use machine learning to build them. Instead of trying to predict and formally define reward events, we can ask humans to evaluate situations and provide supervised information to learn reward functions. For situations where humans can provide such judgments naturally, intuitively, and quickly, RL using such learning-reward models can effectively improve agents (Christiano et al., 2017; Ibarz et al., 2018; Stiennon et al., 2020 Year;)
Many of the factors that lead to the Singularity are yet to be developed, and we can determine what they are with greater certainty than the time frame it takes to implement them. Chris Lattner mentioned "sparsely gated expert composition" from his POV:
To briefly describe it, perhaps there is an intermediary that curates and combines the input of many "experts".
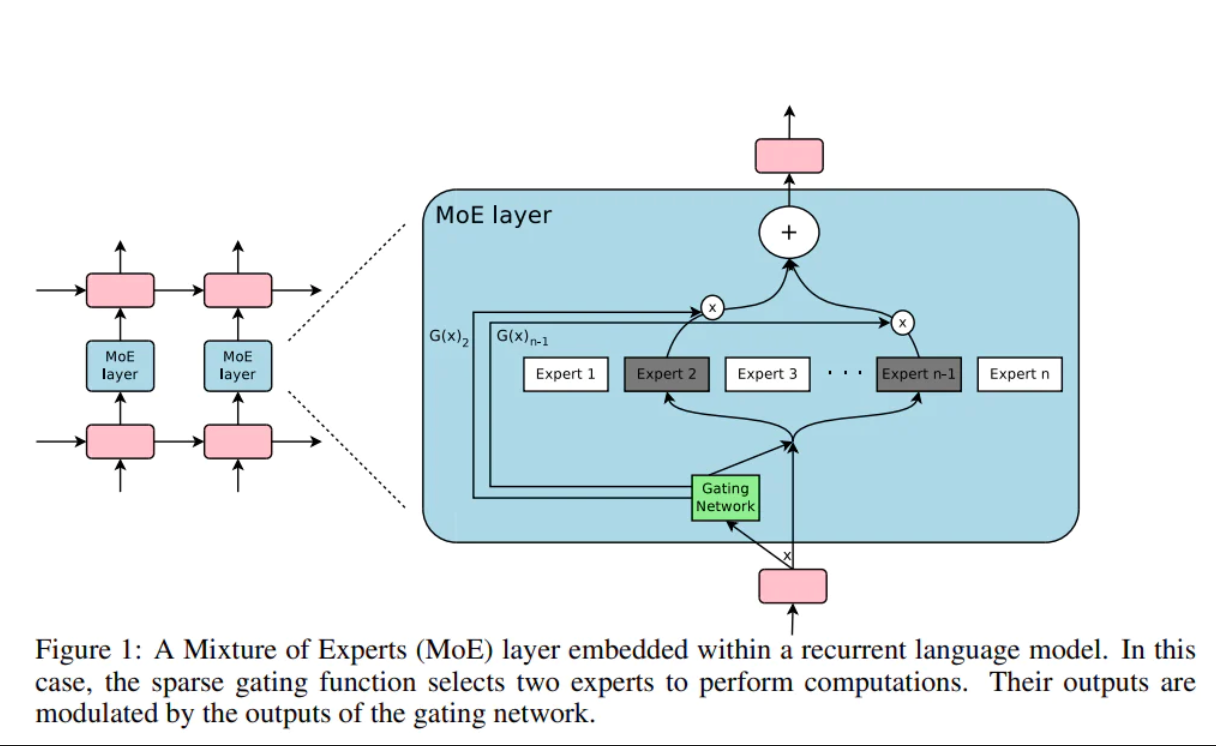
This provides a broad design space for further research. Maybe the middle layer should have chosen differently.
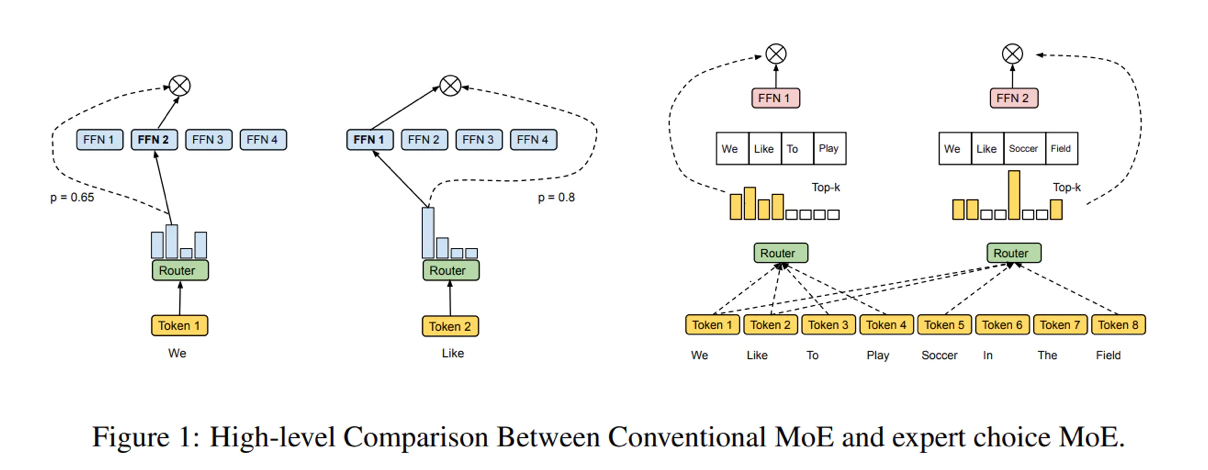
For example, using spatial data.
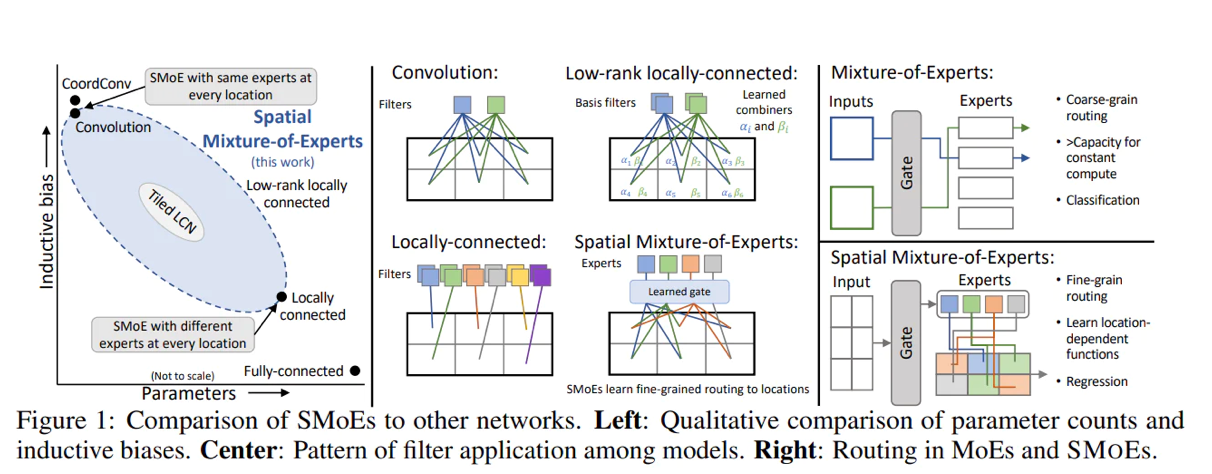
image description
text
text
Feedback from manufacturing has been good, but the health sector has the greatest need. Right now, we're an early adopter of retail biosensors. Over time, homomorphic cryptography will enable machine learning to leverage vast amounts of health data. We have crowdsourced our drug consumption for tens of thousands of years, but it remains to be seen how we will coexist with artificial intelligence that can administer doses of arbitrary substances over any span of time. At the same time, homomorphic encryption is still not used due to efficiency issues.
Google Brain just released Robotics Transformer-1. In the first release it might just be an arm performing simple tasks, but it's clearly possible to iterate with more tokenized operations in a common build environment. Since the global economy is centered around freight, it would make sense if more than 100 "zero-emission" containerships end up being built in such facilities, compared with the roughly 6,000 currently in the world. It would also be a huge change of tide in a housing crisis where zoning ordinances allow it to take full effect.
In addition, I have to mention the Alberta plan, 12 reasonable steps for the development of AGI capabilities.
The term "roadmap" implies drawing a linear path, a series of steps that should be taken and passed in sequence. That's not entirely wrong, but it fails to recognize the uncertainties and opportunities of research. The steps we outline below have multiple interdependencies rather than a sequence of steps from start to finish. The roadmap suggests a natural order, but practice often deviates from this order. Useful research can be done by entering or attaching to any step. As an example, many of us have recently made interesting advances in integrated architectures, although these advances only appeared in the last steps of the sequence.
First, let's try to get a general idea of the roadmap and its rationale. There are twelve steps, titled as follows:
1. Representation I: Continuous Supervised Learning with Given Features. 2. Representation II: Supervised Feature Discovery. 3. Prediction One: Continuous Generalized Value Function (GVF) predictive learning. 4. Control I: Continuous actor-critic control. 5. Prediction two: average reward GVF learning. 6. Control II: Ongoing control issues. 7. Plan I: A plan for equal rewards. 8. Prototype-AI I: Model-Based One-Step Reinforcement Learning with Continuous Function Approximation. 9. Plan II: Search Control and Exploration. 10. Prototype-AI II: STOMP process. 11. Prototype-AI III: Oak. 12. Prototype-IA: Intelligent Amplification.
These steps progress from developing novel algorithms for core capabilities (for representation, prediction, planning, and control) to combining these algorithms to produce complete prototype systems for continuous, model-based AI.
image description

Output of ChatGPT
"Exponential Progress"
The Alberta plan described above is an ideal situation. Humans are already complex, as individuals using sparse neural network tools; as groups, with self-organizing, social learning, and environmental engineering properties. In recent developments in cryptography and distributed (adversarial) computing, humans are only so autonomous as to maintain a Turing-complete global state (history). There is also a phenomenon known as the Mechanical Turk. The point is that AI products drop in any time span, and there will be a mature developer ecosystem that can outperform existing levels with coordinated execution, augmented by contemporaneous AI tools and verifiable work.
This leads to the current thought experiment: Do we even need to achieve every predicted inflection point before The Singularity™? For every proprietary improvement in commercial model training, there may be a viable way to implement it in the public domain. StableDiffusion has sparked conversations around this concept. Crowdsourcing has accelerated sufficiently over the past decade (as evidenced by Twitch Plays Pokemon, Social Networks, and The DAO) that singularity is already a distraction. Just as Ethereum scaling solutions try to use cryptography like zk-SNARKs to reduce the infrastructure needs of the network, we will try to implement lightweight solutions that reduce the need for existing large enterprises to brute force and monetize AI .
In fact, one of the best ways to refute the OpenAI model is that similar social capital systems in financial markets and social networks are somewhat predictable behaviors. Twitter aggregates news because its users can broadcast and amplify it globally with legitimate personalities. With global trends like COVID lockdowns and central bank monetary policy, growth stocks can move sharply higher and lower. It doesn't take much imagination to imagine a startup that can manifest an AI-like PMF as a self-regulating, self-orchestrating community in a fraction of the time. There are potentially hundreds of billions of dollars in operating costs that could be unlocked across many sectors through existing technology and further business development.
In the TV series Westworld, an artificial intelligence system called Rehoboam imposes order on human affairs by analyzing large data sets to manipulate and predict the future. Since the Industrial Revolution, disruptive innovations have repeatedly emerged outside bureaucracies; today, they are happening at an increasing rate. The depth and scope of the public domain has grown in recent decades, and many technologies, no matter how commercial they are, are being forced to open source.