Original Author: Hakeen, W3.Hitchhiker
Original editor: Evelyn, W3.Hitchhiker

1. The upgrade roadmap of Ethereum M2SVPS
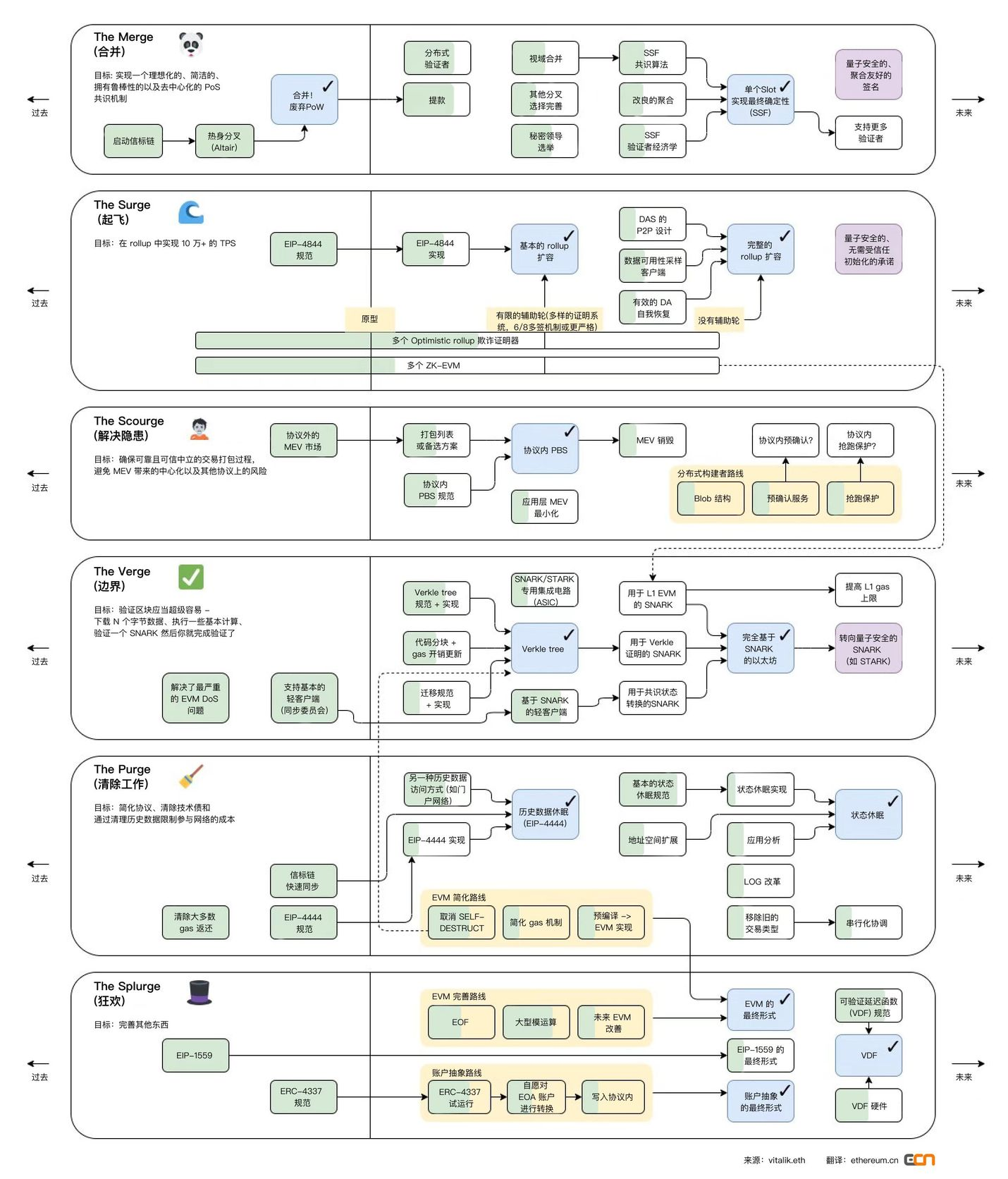
The Merge

In the stage of The Merge, the POW consensus mechanism will transition to POS, and the beacon chain will be merged together. For ease of understanding, we simplify the structure of Ethereum to the following diagram:
Here we first define what fragmentation is: a simple understanding is the process of horizontally splitting the database to spread the load
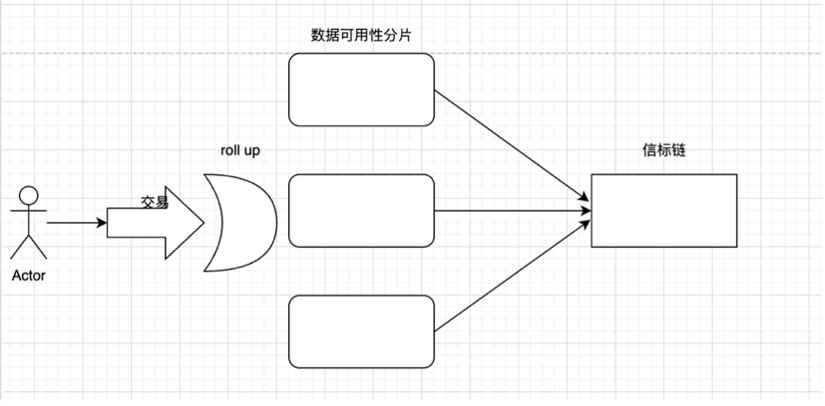
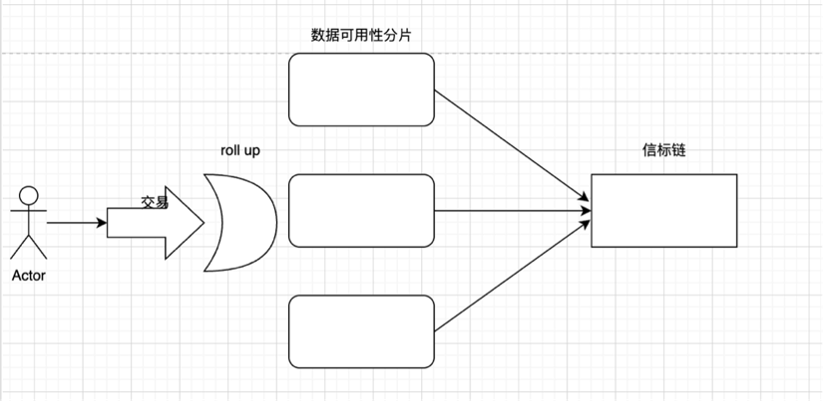
After converting to POS: the block proposer and block verifier are separated, and the POS workflow is as follows (according to the above understanding):
Submit a transaction on Rollup
Validators add transactions to shard blocks
The beacon chain selects validators to propose new blocks
The remaining validators form random committees and validate proposals on the shard
Proposing blocks and proving proposals need to be completed within one slot, usually 12s. Every 32 slots constitute an epoch cycle, and each epoch will disrupt the validator order and re-elect the committee.
After the merger, Ethereum will implement the consensus layerProposer-Builder Separation (PBS). Vitalik believes that the endgame of all blockchains will be to have centralized block production and decentralized block verification. Since the fragmented Ethereum block data is very dense, the centralization of block production is necessary due to the high requirements for data availability. At the same time, there must be a way to maintain a decentralized set of validators that can validate blocks and perform data availability sampling.
Miners and block verification are separated. Miners build blocks and submit them to validators. Bid to validators to choose their own block, and then validators vote to decide whether the block is valid.
Fragmentation is a partitioning method that can distribute computing tasks and storage workloads in a P2P network. After this processing method, each node is not responsible for processing the transaction load of the entire network, but only needs to maintain the data related to its partition (or fragmentation). information is fine. Each shard has its own network of validators or nodes.
Fragmentation security issues: For example, if there are 10 shard chains in the entire network, 51% of the computing power is required to destroy the entire network, and only 5.1% of the computing power is required to destroy a single shard. Therefore, subsequent improvements include an SSF algorithm, which can effectively prevent 51% computing power attacks. according tovitalikIn summary, moving to SSF is a multi-year roadmap, and even with a lot of work done so far, it will be one of the major changes that Ethereum will implement later, and it will be far behind Ethereum's PoS proof mechanism, sharding, and Verkle tree are fully launched after.
The beacon chain is responsible for generating random numbers, assigning nodes to shards, capturing snapshots of a single shard and other various functions, responsible for completing communication between shards, and coordinating network synchronization.
The execution steps of the beacon chain are as follows:
Block producers commit to block headers along with bids.
The block creators (verifiers) on the beacon chain choose the winning block header and bid, regardless of whether the block packager finally generates the block body or not, they will unconditionally receive the winning bid fee.
The Committee (randomly selected among validators) votes to confirm the obtained block header.
The block packer discloses the block body.
The Surge
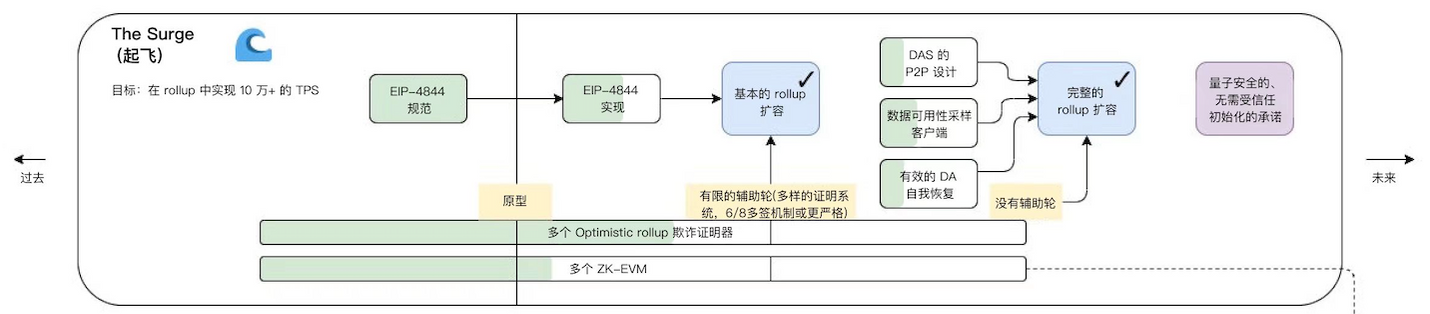
The main goal of this route is to promote Rollup-centric expansion. Surge refers to the addition of Ethereum sharding, which is a scaling solution,Ethereum Foundation claims: This solution will further enable a low-gas-fee layer-2 blockchain, reduce the cost of rollup or bundled transactions, and make it easier for users to operate nodes that secure the Ethereum network.
The diagram can still be understood with the following simplified diagram:
Take the operating principle of zkrollup as an example: zkrollup is divided into a sequencer and an aggregator. The sequencer is responsible for sorting user transactions, packaging them into batches, and sending them to the aggregator. The aggregator executes the transaction, generates the post state root (post state root) from the prev state root, and then generates the proof (proof). The aggregator finally sends the pre-state root, post-state root, transaction data, and proof to L1 The contract on the contract is responsible for verifying whether the proof is valid, and the transaction data is stored in calldata. Zkrollup data availability allows anyone to restore the global state of the account based on the transaction data stored on the chain.
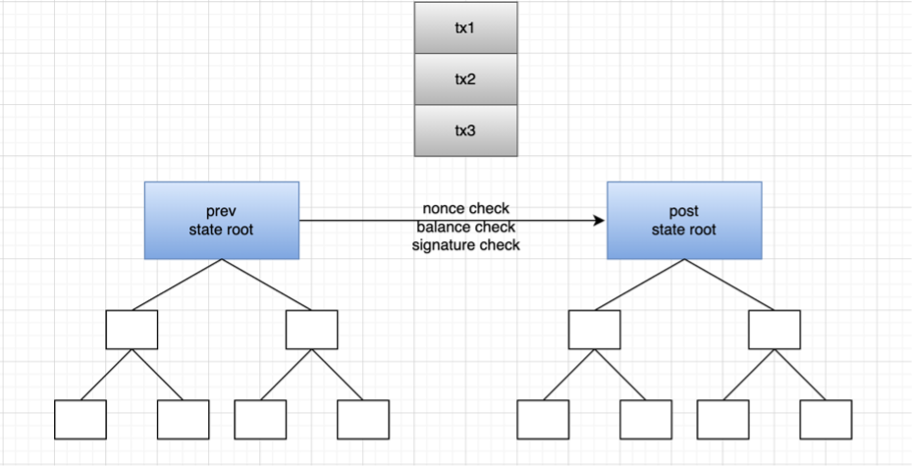
But using calldata is very expensive, so the wholeEIP-4844 protocol(May be changed at any time) It is proposed to change the size of the transaction block to 1-2MB, laying a solid foundation for future rollup and data fragmentation. At present, the block size of Ethereum is about 60KB ~ 100KB. Taking EIP-4844 as an example, the block size limit can be increased by 10 ~ 34x. The block format is called blob (also called data shard).

The Scourge
Scourge at this stage is a supplement to the roadmap and is mainly used to solve the problems of MEV. So what are MEVs?

The full name of MEV is Miner Extractable Value / Maximal Extractable Value. This concept was first applied inproof of workmergemergeAfter the transition to proof-of-stake, validators will be in charge of these roles and mining will no longer apply (the value extraction method described here will remain after this transition, hence the need for a name change). In order to continue using the same acronym to ensure continuity while maintaining the same basic meaning, "Maximum Extractable Value" is now used as a more inclusive alternative.
Arbitrage space includes:
By compressing the storage space, the price difference of the gas fee is obtained;
The referee runs ahead: Extensively search the transactions on the mempool, the machine executes calculations locally to see if it will be profitable, and if so, initiate the same transaction with its own address, and use a higher gas fee;
Finding Liquidation Targets: Bots race to parse blockchain data the fastest to determine which borrowers can be liquidated, then be the first to submit a liquidation transaction and collect their own liquidation fees.
Sandwich transactions: Searchers will monitor the large transactions of DEX in the mempool. For example, someone wants to buy 10,000 UNI using DAI on Uniswap. Such large transactions can have a significant impact on the UNI / DAI pair, potentially significantly increasing the price of UNI relative to DAI. The searcher can calculate the approximate price impact of the large amount transaction on the UNI / DAI pair, and execute the optimal buy order immediately before the large amount transaction, buy UNI at a low price, and then execute the sell order immediately after the large amount transaction, with the large amount order resulting in a higher price to sell.
Disadvantages of MEV:
Some forms of MEV, such as sandwich transactions, can lead to a significantly worse user experience. Users caught in the middle face higher slippage and poorer trade execution. At the network layer, frontrunners in general and their frequent participation in gas auctions (when two or more frontrunners gradually increase the gas fee for their own transactions so that their transactions are included in the next block) lead to Network congestion and high gas fees for others trying to run normal transactions. In addition to what happens within a block, MEV may also have detrimental effects between blocks. If the MEV available in a block greatly exceeds the standard block reward, miners may be incentivized to remine blocks and capture MEV for themselves, leading to blockchain reorganization and consensus instability.
The majority of MEV is extracted by independent network participants called "seekers". Seekers run complex algorithms on blockchain data to detect profitable MEV opportunities, and there are bots that automatically submit these profitable trades to the network. The MEV issue on Ethereum involved the use of bots to exploit network transactions, causing congestion and high fees.
The Verge
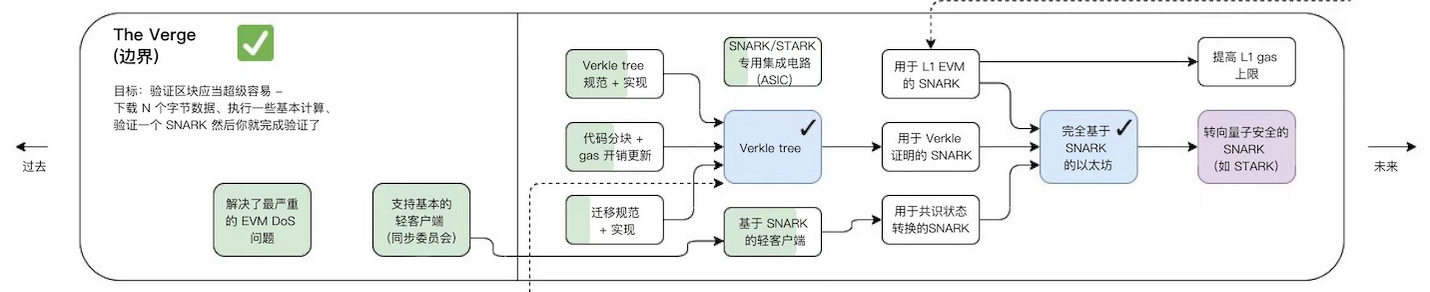
Verge will implement "Verkle tree"(a kind of mathematical proof) and "stateless client". These technical upgrades will allow users to become validators of the network without storing large amounts of data on their machines. This is also one of the steps around the expansion of rollup, mentioned earlier Through the simple working principle of zk rollup, the aggregator submits the proof, and the verification contract on layer 1 only needs to verify the KZG commitment in the blob and the generated proof. Here is a brief introduction to the KZG commitment, which is to ensure that all transactions are included Come in. Because rollup can submit some transactions to generate proofs, if KZG is used, then all transactions will be guaranteed to be included to generate proofs.
The Verge is to ensure that the verification is very simple. You only need to download N bytes of data and perform basic calculations to verify the proof submitted by the rollup.
This articleThis article。
The Purge
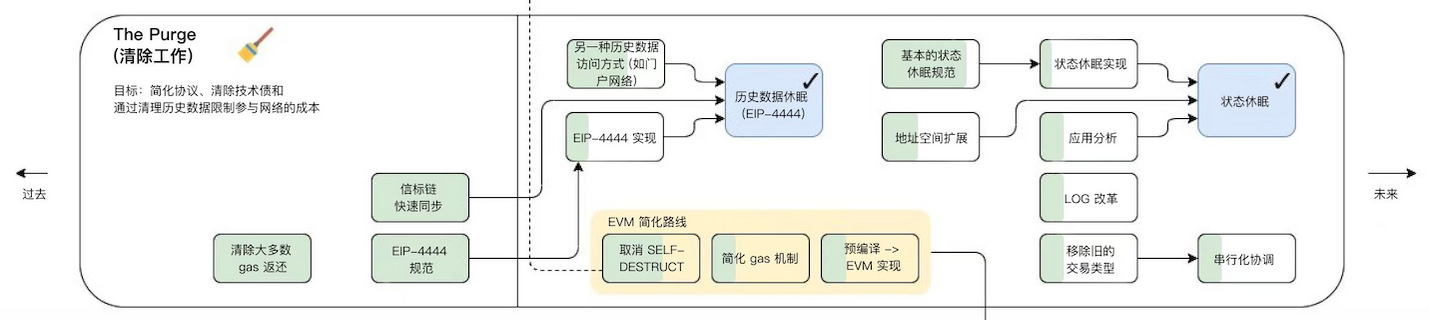
The Purge will reduce the amount of space required to store ETH on a hard drive, attempting to simplify the Ethereum protocol and not requiring nodes to store history. This can greatly increase the bandwidth of the network.
EIP-4444:
Clients MUST stop serving headers, bodies, and recipients older than one year on the P2P layer. Clients can prune these historical data locally. Preserving the history of Ethereum is fundamental, and I believe there are various out-of-band ways to achieve this. Historical data can be packaged and shared via torrent magnet links or networks such as IPFS. Additionally, systems such as Portal Network or The Graph can be used to obtain historical data. The client should allow the import and export of historical data. Clients can provide scripts that fetch/validate data and automatically import them.
The Splurge

This route is mainly some piecemeal optimization fixes, such as account abstraction, EVM optimization, and random number scheme VDF, etc.
The account abstraction (Account Abstraction, AA) mentioned here has always been the goal that Layer 2 of the ZK system wants to achieve first. So what is account abstraction? After implementing account abstraction, a smart contract account can also initiate transactions without relying on the "meta transaction" mechanism (this was proposed in EIP-4844).
In Ethereum, accounts are divided into contract accounts and external accounts. At present, there is only one type of transaction in Ethereum, which must be initiated by an external address, and the contract address cannot actively initiate a transaction. Therefore, any change in the state of the contract itself must depend on a transaction initiated by an external address. Whether it is a multi-signature account, a currency mixer, or any configuration change of a smart contract, it needs to be triggered by at least one external account.
No matter what application is used on Ethereum, users must hold Ethereum (and bear the risk of Ethereum price fluctuations). Secondly, users need to deal with complex fee logic, gas price, gas limit, transaction blocking, these concepts are too complicated for users. Many blockchain wallets or applications try to improve user experience through product optimization, but with little effect.
The goal of the account-centric solution is to create an account for users based on smart contract management. The benefits of implementing account abstraction are:
The current contract can hold ETH and directly submit transactions including all signatures. Users do not necessarily need to pay gas fees for transactions, it all depends on the project.
Due to the implementation of custom cryptography, the use of ESCDA elliptic curves for signatures will not be mandatory in the future. In the future, fingerprint recognition, facial recognition, biometrics and other technologies of a mobile phone can be used as signature methods.
This significantly improves the user experience of interacting with Ethereum.
2. Modularization of Ethereum
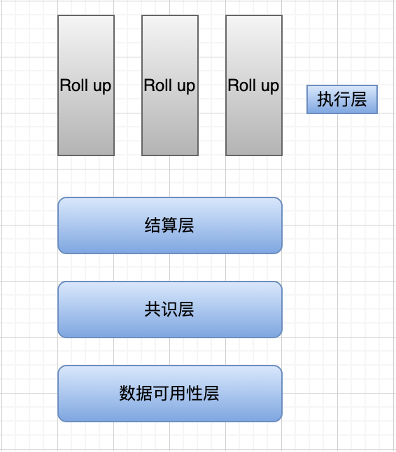
The entire Ethereum has a trend of modularization, and the execution layer is in charge of Layer 2 (such as arbitrum, zksync, starknet, polygon zkevm, etc.). They are responsible for executing transactions of users on L2 and submitting proofs. Layer 2 generally uses OP technology/ZK technology. Theoretically, the TPS of ZK technology is much higher than that of OP. At present, a large number of ecosystems are in the OP system, but in the future, with the improvement of ZK technology, more and more applications will be migrated to the ZK department. This section is a detailed description and supplementary why and how of the roadmap.
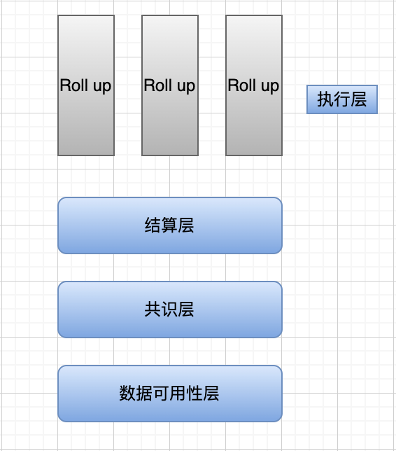
At present, Ethereum only separates the execution layer. In fact, other layers are still mixed up. In Celestia's vision, the execution layer only does two things: for a single transaction, execute the transaction and change the state; for the same batch of transactions, calculate the state root of the batch. Part of the work of the current Ethereum execution layer is assigned to Rollup, which is known to us as StarkNet, zkSync, Arbitrum and Optimism.
Now whether it is optimism, polygon, starknet, zksync, etc., they are all exploring the road of modularization.
Optimism proposes bedrock / op stack, polygon is also developing polygon avail as a data availability layer, and supernets are used to simplify chain creation and share validator sets.
Settlement layer: It can be understood as the process of verifying the above-mentioned pre-state root, post-state root, proof validity (zkRollup) or fraud proof (Optimistic Rollup) by the Rollup contract on the main chain.
Consensus layer: Regardless of PoW, PoS or other consensus algorithms, the consensus layer is to reach a consensus on something in a distributed system, that is, to reach a consensus on the validity of the state transition (the former state is rooted in the post-state after calculation root). In the context of modularization, the meanings of the settlement layer and the consensus layer are somewhat similar, so some researchers have unified the settlement layer and the consensus layer.
Data Availability Layer: Ensure that the transaction data is completely uploaded to the data availability layer, and the verification node can reproduce all state changes through the data in this layer.
What needs to be discriminated here is the difference between data availability and data storage:
Data availability is distinctly different from data storage, where the former is concerned with the availability of data as of the latest block release, while the latter is concerned with storing data securely and ensuring that it can be accessed when needed.
1. Various Rollups on the settlement layer
From the perspective of the settlement layer, it is currently believed that the focus of rollup is on the ZK system. If the size, gas consumption, and cost of the ZK proof system are improved through the rollup of the ZK system, and combined with recursion and parallel processing, its TPS can be greatly expanded. So let's start with ZK rollup.
With the development of the expansion of Ethereum, Zero Knowledge Proof (ZKP) technology is considered by Vitalik to be the solution that is expected to be the end of the expansion battle.
The essence of a ZKP is for someone to prove that they know or have something. For example, I can prove that I have the key to the door without having to take the key out. Proving knowledge of an account's password without having to enter it and risk being exposed is a technology that has implications for personal privacy, encryption, business and even nuclear disarmament. Deepen your understanding with a modified version of Yao's Millionaire Problem: This problem discusses two millionaires, Alice and Bob, who want to know which of them is richer without revealing their actual wealth.
Assuming an apartment rents for $1,000 per month, you would need to pay at least 40 times one month's rent to qualify as a rental candidate. Then we (tenants) need to prove that our annual income must be more than $40,000. But the landlord didn't want us to find loopholes, so he chose not to announce the specific rent. His purpose was to test whether we met the standard, and the answer was only met or not, and he was not responsible for the specific amount.
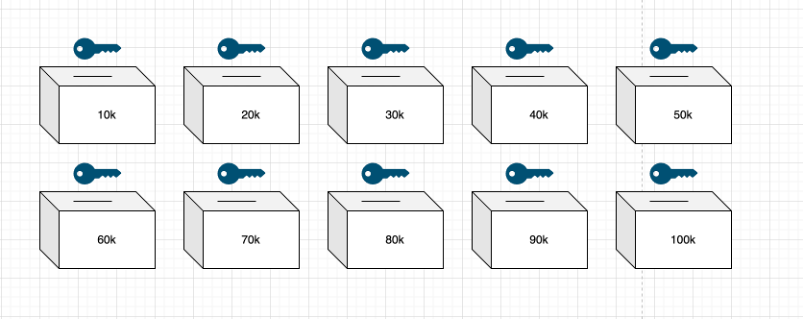
There are now ten boxes marked $10-$100k in increments of $10k. Each has a key and a slot. The homeowner walks into the room with the box and destroys 9 keys, taking the key labeled $40k box.
The tenant's annual salary reaches 75,000 US dollars, and the bank agent supervises the issuance of the asset certification document, without specifying the specific funds. The essence of this document is that the bank's asset statement can verify the claim document. We then drop that file into bins ranging from 10k to 70k. Then when the homeowner uses the 40k key to open the box and sees the verifiable claim documents inside, it is determined that the tenant meets the criteria.
The points involved include that the declarant (bank) issues a certificate of asset compliance, and the verifier (homeowner) verifies whether the tenant is eligible through the key. It is emphasized again that there are only two options for the verification result—qualified and not qualified, and it does not and cannot require the tenant to specify the amount of assets.
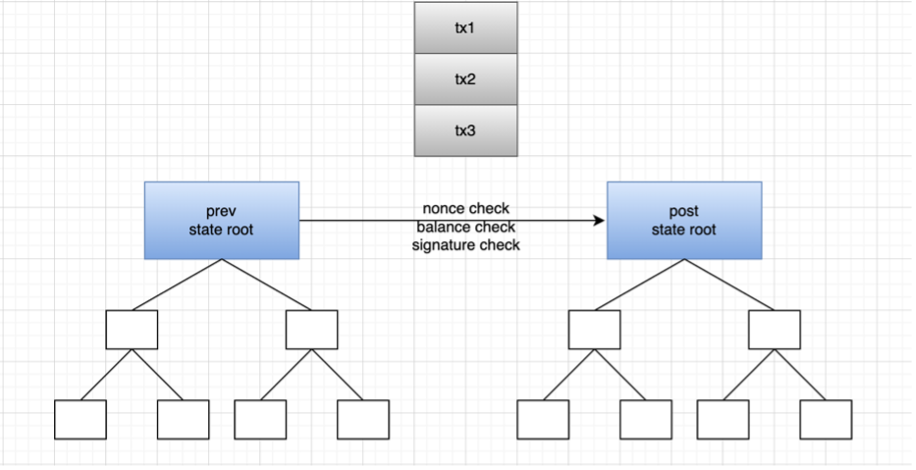
We can still use the following figure as an understanding, the transaction is executed on layer 2, and the transaction is submitted on the shard. Layer 2 generally adopts the form of rollup, that is, multiple transactions are packaged into a batch on layer 2 to process transactions, and then submitted to the rollup smart contract of layer 1. This includes the old and new state roots. The contract on layer 1 will verify whether the two state roots match. If they match, the old state root on the main chain will be replaced with the new state root. Then how to verify that the state root obtained after batch processing is correct? Optimistic rollup and zk rollup are derived here. Use fraud proof and zk technology to confirm the transaction and verify the state root respectively.
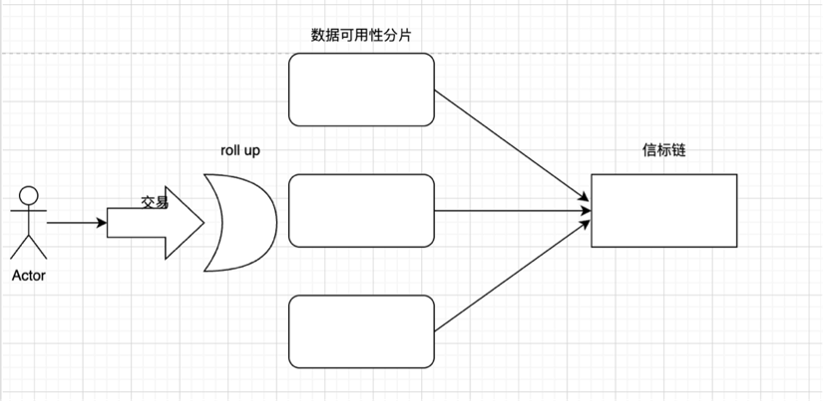
The layer 2 (rollup) here is equivalent to the declarant (bank) in the above example, and its packaging operation is this declaration operation. It does not make a statement on the specific amount, but confirms whether it meets the standard. What is packaged and submitted to layer 1 is this claimable declaration document. The root of verifying the old and new status is that the homeowner uses the key to verify whether the economic strength of the tenant he expects meets the standard. The state root verification problem is the statement submitted by the bank, how to make the statement to make the problem credible.
Based on an optimistic rollup that is fraud proof, the Rollup contract of the main chain records the complete record of the internal state root change of the Rollup, as well as the hash value of each batch (triggering the state root change). If someone finds that the new state root corresponding to a batch is wrong, they can post a proof on the main chain that the new state root generated by the batch is wrong. The contract verifies the proof, and if the verification is passed, all batch processing transactions after the batch processing will be rolled back.
The verification method here is equivalent to that the declarant (bank) submits a verifiable asset declaration document, and then publishes all the asset documents on the chain, and the data is also published on the chain, and other challengers perform calculations based on the original data to see the verifiable Whether there are errors or forgery in the asset documents, if there is a problem, then challenge it, if the challenge is successful, claim to the bank. The most important issue here is to allow time for the challenger to collect data and verify the authenticity of the document.
For Rollup using Zero Knowledge Proof (ZKP) technology, each batch contains a cryptographic proof called ZK-SNARK. Banks generate asset declaration documents through cryptographic proof technology. In this way, there is no need to reserve time for the challenger, so the role of the challenger does not exist.
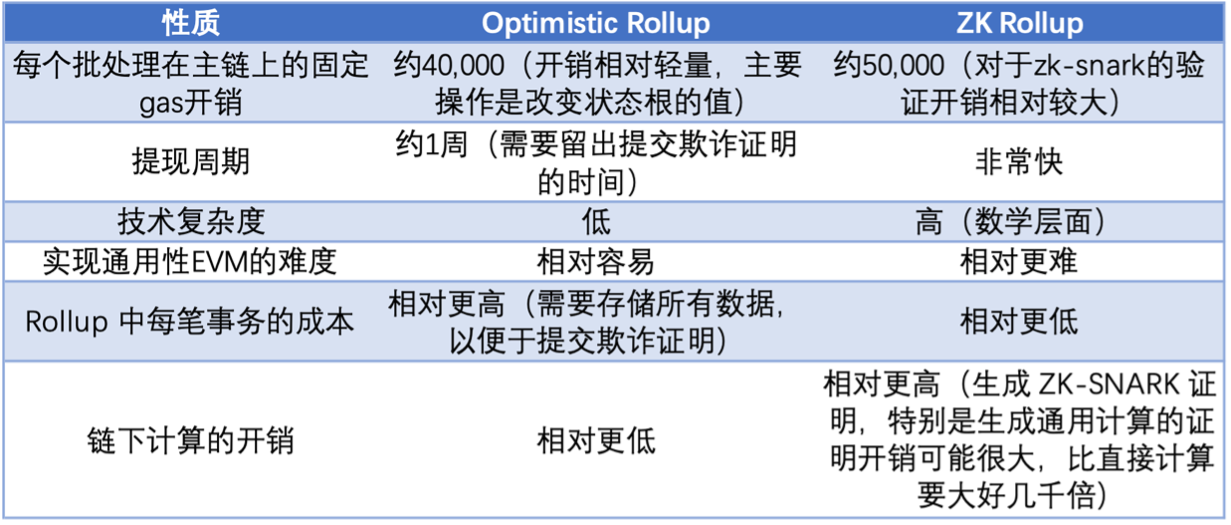
2. The current ZK system Rollup is not as expected
At present, the hermez of the polygon series has been released, and the zksync dev mainnet and starknet mainnet have also been launched. But their transaction speed seems to be far from our theory, especially starknet users can clearly perceive that its mainnet speed is surprisingly slow. The reason is that it is still very difficult to generate proofs with zero-knowledge proof technology, the cost is still high, and there is a need to balance the compatibility of Ethereum and the performance of zkevm. The Polygon team also admits: "The testnet version of the Polygon zkEVM also has limited throughput, meaning it is far from final as an optimized scaling machine.”
3. Data Availability Layer
The abstract execution steps of Ethereum are as follows:
In the process of decentralization in Ethereum, we can also see it on The Merge roadmap - decentralized validators. The most important of these is to realize the diversity of clients, lower the entry threshold of machines, and increase the number of verifiers. Therefore, if some verifiers whose machines are not up to standard want to participate in the network, they can use the light client. The operating principle of the light node is to ask for the block header through the adjacent full nodes. The light node only needs to download and verify the block header. If the light nodes do not participate, then all transactions need to be verified by the full node, so the full node needs to download and verify each transaction in the block. At the same time, as the transaction volume increases, the full node is under more and more pressure. Large, so the node network gradually tends to be high-performance and centralized.
But the problem here is that malicious full nodes can give missing/invalid block headers, but light nodes have no way to falsify. There are two ways to solve this problem. At first, fraud proofs were used, which required a credible full node to Monitor the validity of the block, construct a fraud proof after finding an invalid block, and judge it as a valid block header if the fraud proof is not received within a period of time. But a trusted full node is obviously required here, that is, trusted settings or honest assumptions are required. However, the block producer can hide some transactions, and the fraud proof is obviously invalid, because the honest node also depends on the data of the block producer. If the data itself is hidden, then the trusted node believes that the submitted data is all data , then naturally no fraud proof will be generated.
Mustarfa AI-Bassam and Vitalik propose a new solution - erasure coding - in a paper co-authored. Erasure codes are used to solve the problem of data availability. For example, celestia and polygon avail use reed-solomon erasure codes. But how to ensure that the transmitted data is complete data, combined with KZG commitment/fraud proof.
In the KZG commitment/fraud proof, it is possible to ensure that block producers publish complete data without hiding transactions, and then encode the data through erasure codes, and then sample data availability, so that light nodes can correctly verify the data .
The data submitted by the aggregator in Rollup is stored on the chain in the form of calldata, because calldata data is cheaper than other storage areas.
Calldata cost in gas = Transaction size × 16 gas per byte
The main overhead of each transaction is the cost of calldata, because storage on the chain is extremely expensive, and this part accounts for as much as 80% to 95% of the cost of rollup.
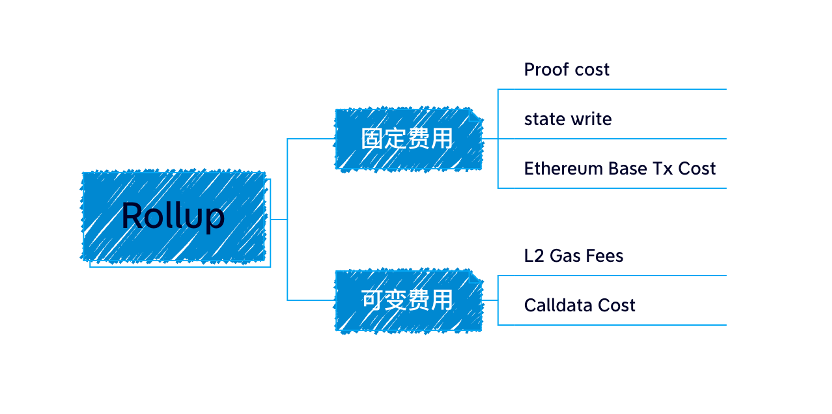
Because of this problem, we proposed the new transaction format blob of EIP-4844, which expands the block capacity and reduces the gas fee required to submit to the chain.
4. On-chain and off-chain of data availability layer
So how to solve the problem of expensive data on the chain? There are several methods:
The first is to compress the size of the calldata data uploaded to L1. There have been many optimizations in this regard.
The second is to reduce the cost of storing data on the chain, and provide "big blocks" for rollup through Ethereum's proto-danksharding and danksharding, with larger data availability space, and use erasure codes and KZG commitments to solve the problem of light nodes . Such as EIP-4844.
The third is to put data availability off the chain. The general solutions for this part include celestia / polygon avail, etc.
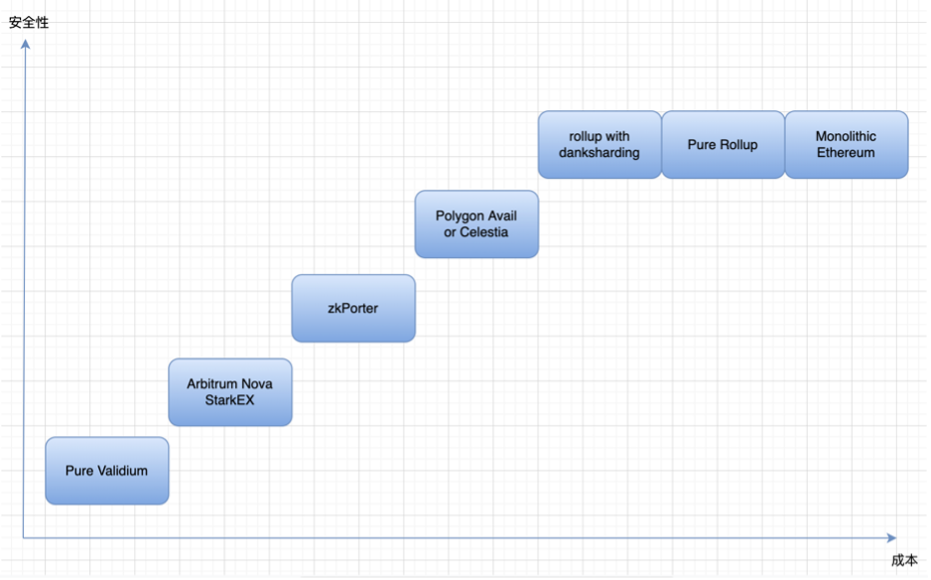
By the location where data availability is stored, we divide it into the following figure:
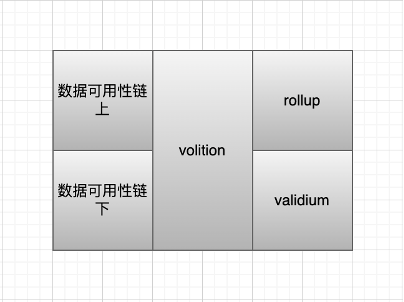
Validium's solution: put data availability off-chain, then these transaction data will be maintained by centralized operators, and users need trusted settings, but the cost will be very low, but at the same time there is almost no security. Later, both starkex and arbitrum nova proposed to set up DAC to be responsible for the storage of transaction data. DAC members are well-known individuals or organizations within the legal jurisdiction, and the trust assumption is that they will not collude and do evil.
Zkporter proposes guardians (zksync token holders) to pledge to maintain data availability. If a data availability failure occurs, the pledged funds will be forfeited. Volition is the user's choice of on-chain/off-chain data availability, and choose between security and cost according to needs.
At this time, celestia and polygon avail appeared. If validium has the requirement of off-chain data availability and fears that the degree of decentralization will be low, which will lead to private key attacks similar to cross-chain bridges, then the decentralized general DA solution can solve this problem. Celestia and polygon avail provide validium with an off-chain DA solution by becoming a separate chain. But through a separate chain, although the security is improved, the cost will be increased accordingly.
The expansion of Rollup actually has two parts, one is the execution speed of the aggregator, and the other requires the cooperation of the data availability layer. Currently, the aggregator is run by a centralized server, assuming that the speed of transaction execution can reach an infinite degree. , then the main scaling dilemma is that it is affected by the data throughput of the underlying data availability solution. How to maximize the data space throughput of a data availability solution is critical if a rollup is to maximize its transaction throughput.
Going back to the beginning, use KZG commitments or fraud proofs to ensure data integrity, and expand transaction data through erasure codes to help light nodes sample data availability to further ensure that light nodes can correctly verify data.
You may also want to ask, how does the KZG commitment work to ensure the integrity of its data? Maybe a little bit of an answer:
KZG Promise: Prove that the value of a polynomial at a specific position is consistent with a specified value.
KZG commitment is nothing more than a kind of polynomial commitment, which can verify the message without giving a specific message. The approximate process is as follows:
Convert the data into a polynomial through erasure coding and expand it. Using KZG promises to ensure that our extensions are valid and the original data is valid. Then use the extension to reconstruct the data, and finally perform data availability sampling.
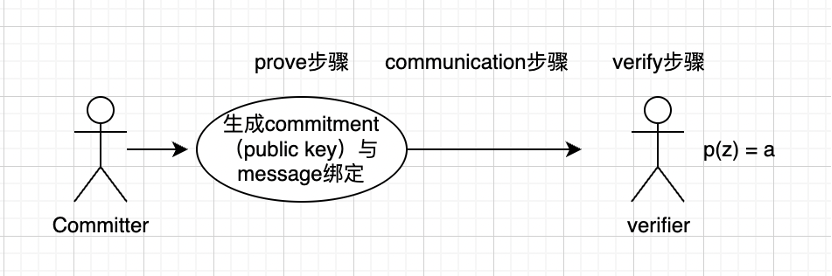
A committer generates a commitment and binds it to a message.
Send the bound message to the verifier. The communication scheme here is related to the size of the proof size.
Verifier (verifier), multiple values brought into the finite field to verify whether it is still equal to a (this is the process of usability sampling), the basic principle is that the more times of verification, the higher the probability of being correct.
Celestia requires validators to download entire blocks, and today's danksharding utilizes data availability sampling techniques.
Since the block is partially available, we need to ensure synchronization when reconstructing the block at any time. When the block is indeed partially available, the nodes communicate with each other to piece the block together.
Comparison of KZG Promise and Data Fraud Proofs:
It can be seen that KZG promises to ensure that the expansion and data are correct, and the fraud proof introduces a third party for observation. The most obvious difference is that fraud proofs need a time interval to respond to observers before reporting fraud. At this time, nodes need to be directly synchronized so that the entire network can receive fraud proofs in a timely manner. KZG is significantly faster than fraud proof, which uses mathematical methods to ensure the correctness of data without a waiting period.
It can justify the data and its extension. However, because the one-dimensional KZG commitment needs to consume more resources, Ethereum chooses the two-dimensional KZG commitment.
For example, 100 rows × 100 columns, that is 100,00 shares (shares). But every sampling is not a one in ten thousand guarantee. Then the expansion of four times means that at least 1/4 of the entire share must be unavailable, and you may draw an unavailable share, which means that it is really unavailable, because it cannot be recovered. Only when 1/4 is unavailable can it be recovered, it is really effective to find errors, so the probability of drawing once is about 1/4. Pumping more than ten times, fifteen times, can reach 99% reliability guarantee. Now make choices in the range of 15–20 times.
5、EIP-4844(Proto-Danksharding)
In a proto-danksharding implementation, all validators and users must still directly verify the availability of the full data.
The main feature introduced by Proto-danksharding is a new transaction type, which we call blob-carrying transactions. A transaction with a blob is similar to a regular transaction, except that it also carries an additional piece of data called a blob. Blobs are very large (~125 kB) and are much cheaper than calling data for a similar amount. However, these blobs are not accessible from the EVM (only promises to blobs). And blobs are stored by the consensus layer (beacon chain) instead of the execution layer. This is actually the beginning of the gradual formation of the concept of data sharding.
Because validators and clients still need to download the full blob content, the data bandwidth target in proto-danksharding is 1 MB per socket instead of the full 16 MB. However, since these figures do not compete with the gas usage of existing Ethereum transactions, there are still large scalability gains.
While implementing full sharding (using data availability sampling, etc.) was a complex task, and remains a complex task after proto-danksharding, this complexity is contained in the consensus layer. Once proto-danksharding is rolled out, no further work is required from the executive layer client team, rollup developers, and users to complete the transition to full sharding. Proto-danksharding also separates blob data from calldata, making it easier for clients to store blob data in less time.
It's worth noting that all work is done by the consensus layer without any additional work being performed by the client team, users, or Rollup developers.
Both EIP-4488 and proto-danksharding lead to a long-term maximum usage of about 1 MB per socket (12 seconds). This equates to roughly 2.5 TB per year, well above the growth rate Ethereum needs today.
In the case of EIP-4488, a history expiry proposal is required to fix thisEIP-4444(mentioned in the roadmap section), where clients are no longer required to store history beyond a certain time period.
6. Data fragmentation
Here, I will explain as much as possible from the perspective of Xiaobai the issues that everyone is discussing during the expansion of Ethereum. So let's go back to sharding, and once again emphasize the one-sided concept of sharding: a simple understanding is the process of horizontally splitting the database to spread the load.
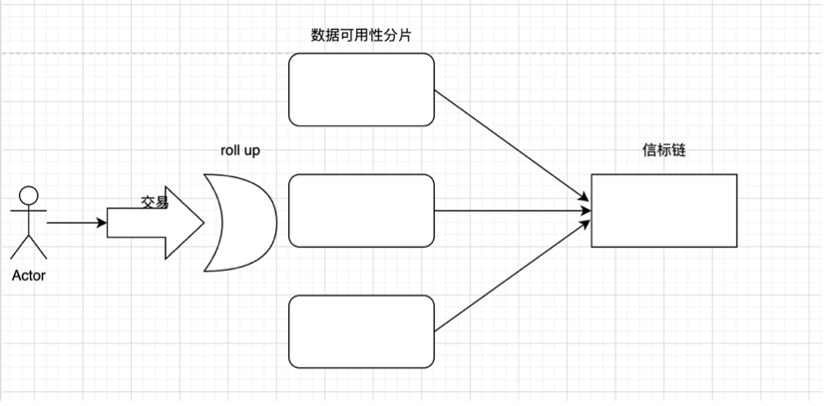
Here, a very important problem with our data sharding is that in PBS (the proposer is separated from the block builder, as mentioned in the roadmap The Merge), in sharding, each node group only processes The transactions in this shard will be relatively independent between the shards, so how should the two users of AB and AB be in different shards and transfer funds to each other? Then there is a need for good cross-chip communication capabilities.
The old way was to shard the data availability layer, each with independent proposers and committees. In the set of verifiers, each verifier takes turns to verify the data of the fragment, and they download all the data for verification.
weakness is:
Strict synchronization technology is required to ensure that validators can be synchronized within a slot.
The validator needs to collect all committee votes, and there will be a delay here.
And the verifier is under great pressure to download the data completely.
The second approach is to forego full data validation and instead use data availability sampling (which was implemented later in The Surge). Here are divided into two random sampling methods, 1) block random sampling, sampling part of the data slice, if the verification is passed, the verifier will sign. But the problem here is that there may be cases where transactions are missed. 2) Reinterpret data into polynomials through erasure codes, and then use the characteristics of polynomials that can restore data under certain conditions to ensure the complete availability of data.
"Fragmentation"The point is that validators are not responsible for downloading all data, and this is why Proto-danksharding is not considered a"Fragmented"(despite its name having"Shard sharding"first level title
3. Layer 3 of the future of Ethereum
Layer 2 of the ZK series, which is regarded as the future expansion of Ethereum, such as zksync and starknet, have all proposed the concept of Layer 3. A simple understanding is Layer 2 of Layer 2.
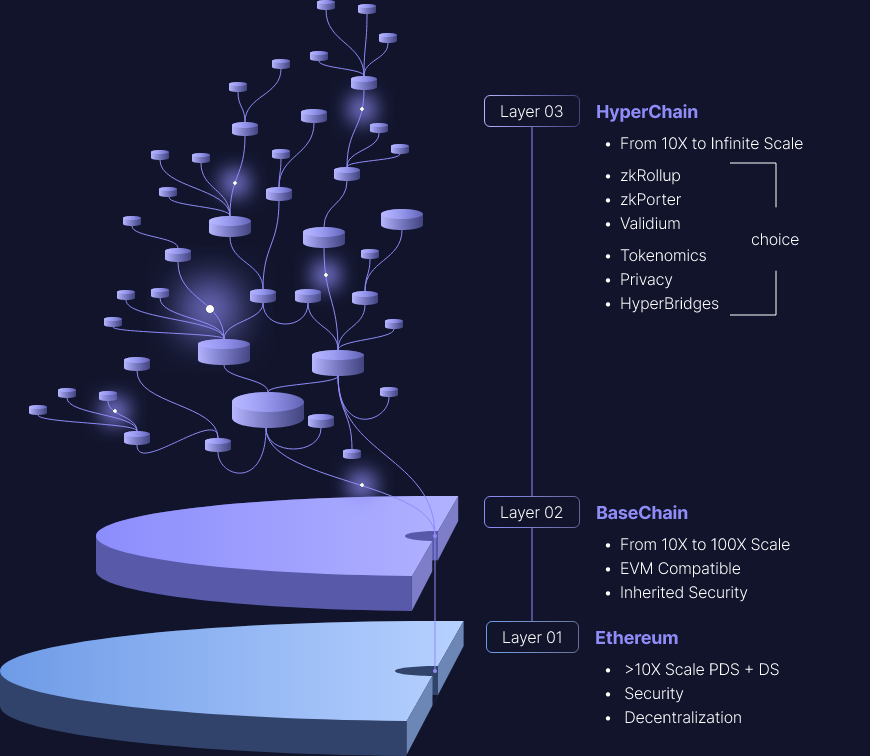
High transaction costs on Ethereum are pushing it (L3) to become the settlement layer for L2. It is believed that in the near future, due to the significant reduction in transaction costs, the increasing support for DeFi tools, and the increased liquidity provided by L2, end users will conduct most of their activities on L2, and Ethereum will gradually become the settlement layer.
L2 improves scalability by reducing gas costs per transaction and increasing transaction rates. At the same time, L2s retains the benefits of decentralization, general logic, and composability. However, certain applications require specific customization, which may be better served by a new independent layer: L3!
L3 is related to L2, just like L2 is related to L1. As long as L2 can support the verifier (Verifier) smart contract, L3 can use validity proof to achieve. When L2 also uses validity proofs submitted to L1, as StarkNet does, this becomes a very elegant recursive structure, where the compression advantage of L2 proofs is multiplied by the compression advantage of L3 proofs. In theory, if each layer achieves, say, a 1000x cost reduction, then L3 could be 1,000,000x lower than L1 -- while still maintaining the security of L1. This is also a real use case of the recursive proof that starknet is proud of.
Part of the knowledge of "On-chain and Off-chain of Data Availability Layer" is needed here. The entire Layer 3 includes:
Rollup (on-chain data availability), validium (off-chain data availability). The two correspond to different application requirements. Web2 companies that are sensitive to prices and data can use validium to put data off-chain, which greatly reduces gas costs on the chain, and can not disclose user data to achieve privacy, allowing companies to complete their own control over data. Using a custom data format, the data business model of the previous enterprise can still run smoothly.
L2 is for extensions, and L3 is for custom features, such as privacy.
In this vision, there is no attempt to provide "quadratic scalability"; instead, there is a layer in this stack that helps the application scale, and then the layers are separated according to the customized functional requirements of different use cases.
L2 is for common extensions and L3 is for custom extensions.
Custom extensions may come in different forms: specialized applications that use something other than the EVM for computation, rollups whose data compression is optimized for a specific application's data format (including separating "data" from "proofs", and completely replace the proof with a single SNARK per block), etc.
L2 is used for trustless expansion (rollup), and L3 is used for weak trust expansion (validium).
Validium is a system that uses SNARKs to verify computations, but leaves data availability to trusted third parties or committees. In my opinion, Validium is grossly underrated: in particular, many "enterprise blockchain" applications might actually be best served by a centralized server running a validium prover and periodically submitting hashes to the chain . Validium is less secure than rollup, but can be much cheaper.
For dApp developers, there are several options for infrastructure:
Develop a Rollup yourself (ZK Rollups or Optimistic Rollups)
The advantage is that you can inherit the ecology (users) of Ethereum and its security, but for a dApp team, the development cost of Rollup is obviously too high.
Choose Cosmos, Polkadot or Avalanche
The cost of development will be lower (for example, dydx chose Cosmos), but you will lose the ecology (users) and security of Ethereum.
Develop a Layer 1 blockchain by yourself
The development costs and difficulties brought about are high, but they can have the highest control.
Let's compare three cases:
Difficulty/Cost: Alt-layer 1 > Rollup > Cosmos
Security: Rollup > Cosmos > Alt-layer 1
Ecology/User: Rollup > Cosmos > Alt-layer 1
Control: Alt-layer 1 > Cosmos > Rollup
first level title
4. Future development of Layer 2
Since Ethereum is designed based on the account model, all users are in an entire state tree, so parallelism cannot be performed. Therefore, the shackles of Ethereum itself make it necessary to strip execution operations and combine multiple rollup transactions into one Transactions exist as a settlement layer. Now all the problems are focused on improving the throughput of layer 2. Not only can layer 3 improve transaction throughput, but also parallel processing on layer 2 can greatly increase the throughput of the entire network.
Starknet is also actively exploring the parallelization problem. Although it is proved that the algorithm is still a shackle, it is not expected to become a resistance in the future. Potential bottlenecks include:
The sorter tx handles:Some sorter jobs seem to be inherently serial.
bandwidth:Interconnection between multiple sequencers will be limited.
L2 state size
In the starknet community, members also raisedParallel processing in aptosfirst level title
V. Summary
Ethereum is stripping away the execution layer, all in the direction of its vision of a "global" settlement layer. Although the progress of the entire Ethereum is slow at present, it is because its overall size is too large, and each update involves many interests and trade-offs. However, it is undeniable that Ethereum is undergoing major changes. There are a large number of activities on the chain of Ethereum, the improvement of economic mechanisms, and the scalability of Ethereum 2.0. expect. It is believed that as more and more countries deploy Ethereum nodes, such asArgentine Capital Government Plans to Deploy Ethereum Validator Nodes in 2023Original link