Original translation: Tia
Original translation: Tia
image description
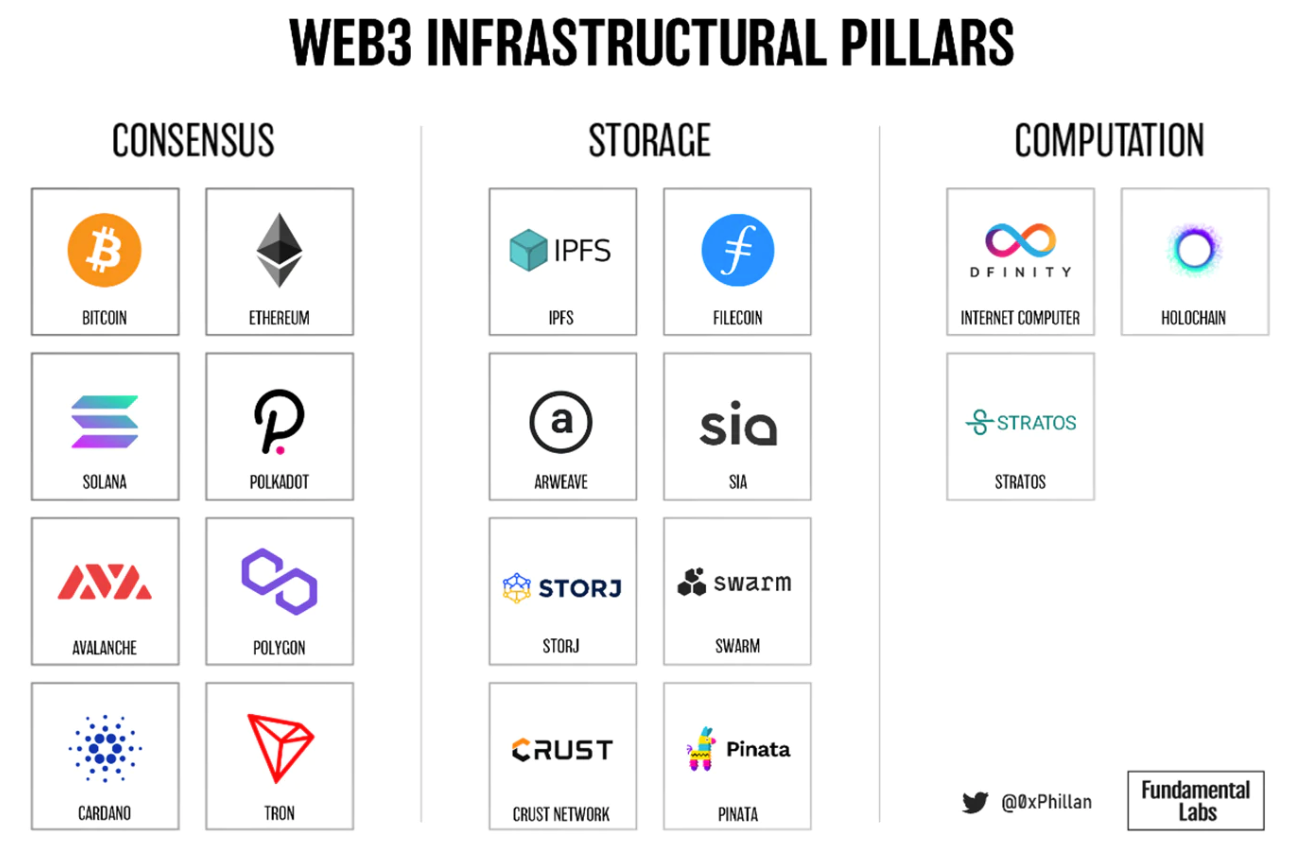
Figure 1: Example projects for each Web3 pillar
Storage, as the second pillar, is rapidly maturing, and various storage solutions have been applied to usage scenarios. In this article, the pillar of decentralized storage will be further explored.
andArweaveandCrust Networkdownload.
The need for decentralized storage
Blockchain Perspective
From the perspective of the blockchain, we need decentralized storage because the blockchain itself is not designed to store large amounts of data. The mechanism for obtaining block consensus relies on small amounts of data (transactions), which are placed in blocks (collection transactions), and quickly shared to the network for node verification.
image description
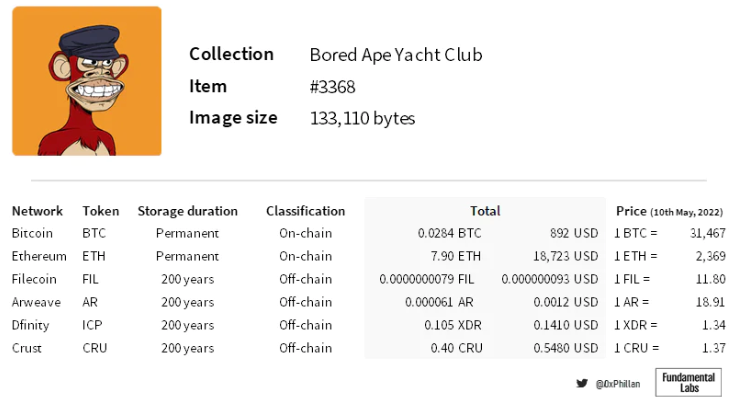
Figure 2: Projects with an active mainnet. A storage period of 200 years was chosen to meet Arweave's definition of permanence. Sources: web docs, Arweave storage calculator
Second, if we want to store a large amount of arbitrage data in these blocks, network congestion will become severe, which will cause gas wars when using the network and cause prices to increase. This is a consequence of the implicit time value of blocks, if users need to submit transactions to the network at a certain time, they will need to pay extra gas fees to have their transactions prioritized.
Therefore, it is recommended to store NFT metadata and image data, and the front end of dApp off-chain.
The Perspective of the Centralized Network
If storing data on-chain is so expensive, why not just store it off-chain in a centralized network?
Centralized networks are prone to censorship and variability. This requires users to trust the data provider to maintain the security of the data. There is no guarantee that the operators of centralized networks will truly live up to the trust their users have placed in them: data can be wiped intentionally or accidentally. For example, it may be due to data provider policy changes, hardware failure, or attacks by third parties.
NFTs
image description
Figure 3: Crypto Punk reserve price based on last sale (no reserve price at time of writing); Crypto Punk image size based on byte length of byte string on Crypto Punks V2 chain. Data as of May 10, 2022. Source: OpenSea, on-chain data, IPFS metadata
image description
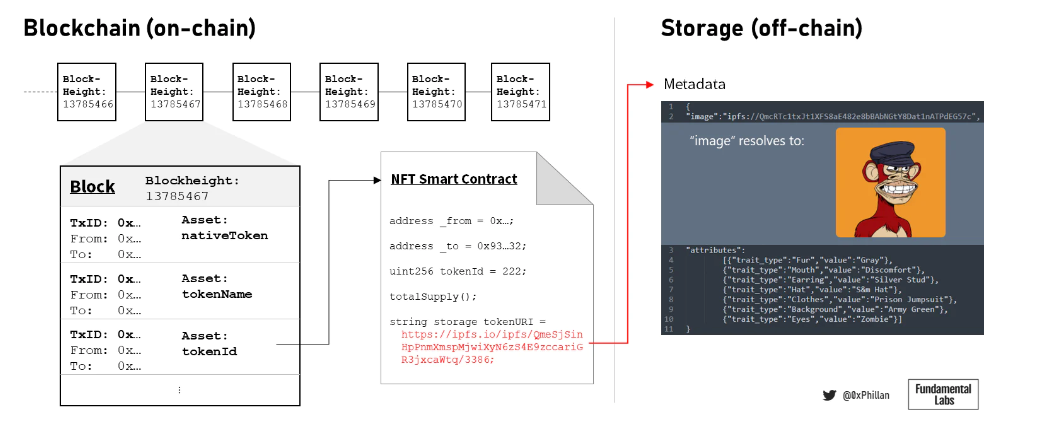
Figure 4: Simplified illustration of blockchain, blocks, NFTs, and off-chain metadata
Arguably, the value of NFTs is not primarily driven by the metadata and image data they refer to, but rather by the movement and ecosystem community that drives the collection. While this may be true, NFTs are meaningless without underlying data, and meaningless communities simply cannot form.
In addition to profile pictures and art collectibles, NFTs can also represent ownership of real-world assets, such as real estate or financial instruments. In addition to the external real-world value of such data, since its value is represented by NFT, the value of each byte of data saved in NFT will not be lower than the value of NFT on the chain.
dApps
image description
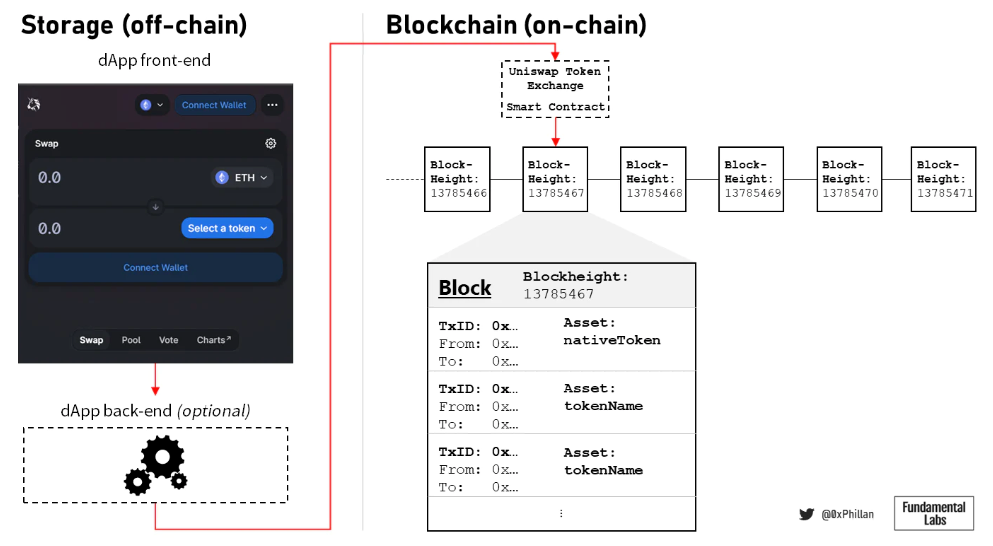
Figure 5: Simplified illustration of a dApp interacting with the blockchain
image description
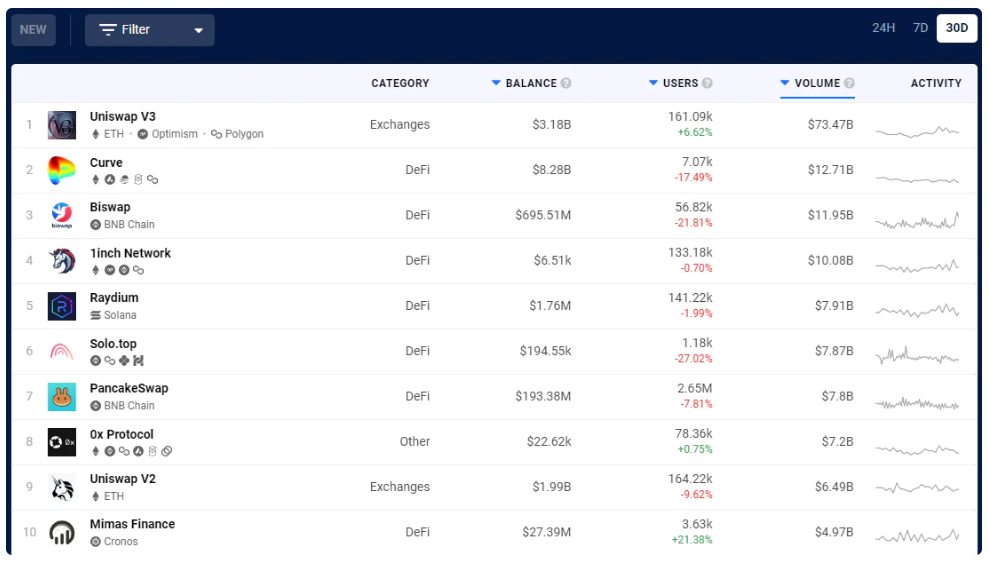
Figure 6: Most popular dApps by USD volume, as reported by DappRadar as of May 11, 2022
image description
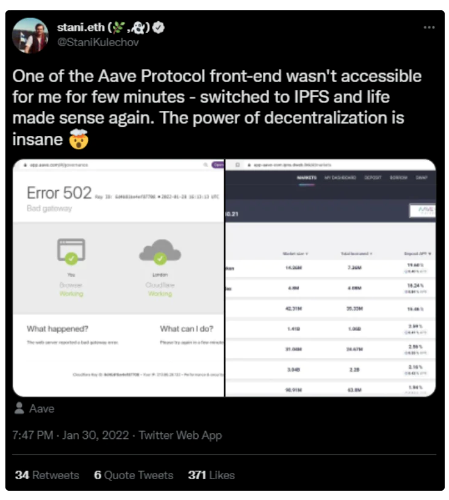
Figure 7: Aave founder Stani Kulechov tweeted that the Aave dApp front-end will go offline on January 20, 2022, but will still be accessible via an IPFS-hosted copy of the website
Decentralized storage reduces server failures, DNS hacks, and centralized entities removing access to the dApp frontend. Even if the development of the dApp is stopped, smart contracts can continue to be accessed through the front end.
Decentralized storage landscape
image description
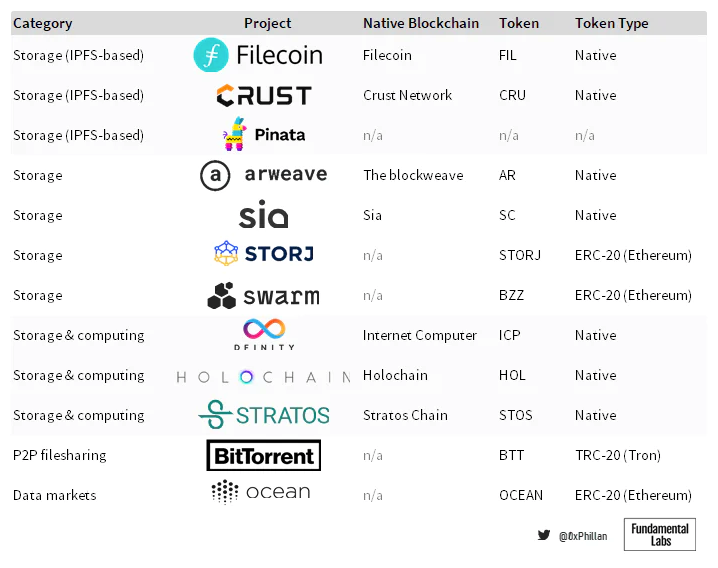
Figure 8: Overview (non-exhaustive) of some arbitrarily chosen decentralized storage protocols
Despite the many differences, all of the above projects have one thing in common: none of these networks replicate all data on all nodes, which is the case with the Bitcoin and Ethereum blockchains. In a decentralized storage network, the immutability and availability of stored data is not achieved by most networks storing and validating successively linked data, as is the case with Bitcoin and Ethereum. Although as mentioned earlier, many networks choose to use the blockchain to track storage orders.
It is unsustainable for all nodes on a decentralized storage network to store all data, because the indirect cost of running the network will quickly increase the storage cost of users, and eventually drive the centralization of the network to a small number of nodes that can afford the hardware costs. node operator.
Therefore, decentralized storage networks need to overcome extraordinary challenges.
Challenges of Decentralized Storage
Reviewing the previously mentioned limitations regarding on-chain data storage, it is clear that a decentralized storage network must store data in a way that does not affect the network's value transfer mechanism, while ensuring that data remains persistent, immutable, and accessible. In essence, a decentralized storage network must be able to store data, retrieve data, and maintain data, while ensuring that all participants in the network are incentivized for the storage and retrieval work they do, while also maintaining a decentralized system distrust.
These challenges can be summarized as the following questions:
Data storage format: store complete files or file fragments?
Data replication: across how many nodes to store data (full files or fragments)?
Storage Tracking: How does the network know where to retrieve files from?
Proof of stored data: Are nodes storing the data they are asked to store?
Data Availability Over Time: Is the data still stored over time?
Storage Price Discovery: How Are Storage Costs Determined?
Persistent Data Redundancy: If a node leaves the network, how does the network ensure that data is still available?
Data Transfer: Network bandwidth comes at a price - how do you ensure nodes retrieve data when asked?
Network Token Economics: In addition to ensuring that data is available on the network, how can the network ensure the long-term existence of the network?
image description
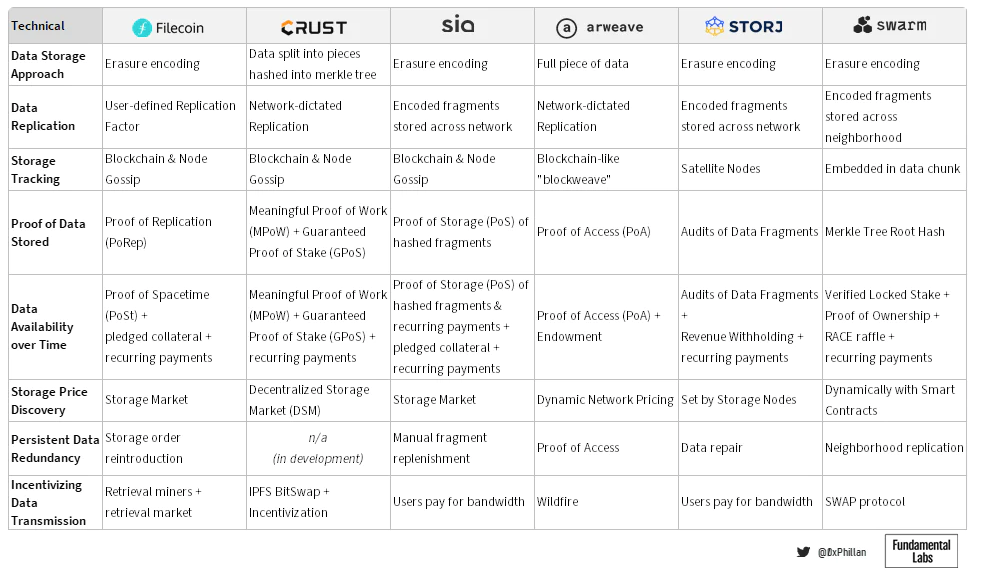
Figure 9: Summary of Technical Design Decisions for Audited Storage Networking
orArweaveorCrust NetworkRead the full research article.
image description
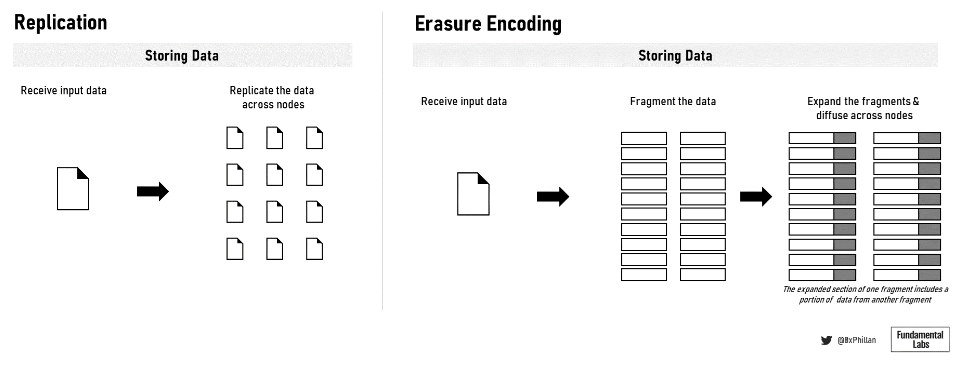
Figure 10: Data replication and erasure coding
In these networks, there are two main methods used to store data on the network: storing full files and using erasure coding: Arweave and Crust Network store full files, while Filecoin, Sia, Storj, and Swarm all use erasure coding . In erasure coding, data is broken into fixed-size pieces, each piece is expanded and encoded with redundant data. The redundant data saved into each fragment makes it necessary to reconstruct the original file only a subset of the fragments.
data replication
image description
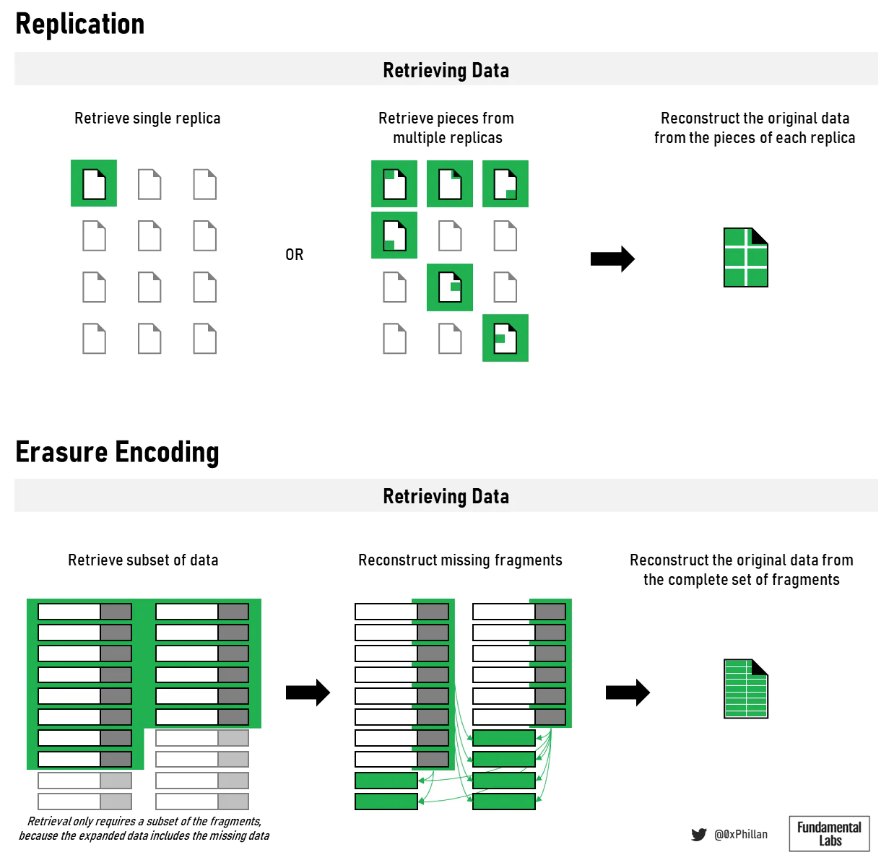
Figure 11: Data storage format will affect retrieval and reconstruction
The method used to store and replicate data will affect how the network retrieves it.
storage tracking
image description
Figure 12: Illustration of three nodes in blockweave
In the end, Storj and Swarm take two completely different approaches. In Storj, a second node type called a satellite node acts as a coordinator for a group of storage nodes, managing and tracking where data is stored. In Swarm, the address of the data is directly embedded in the data block. When retrieving data, the network knows where to look based on the data itself.
Proof of stored data
Each network takes its own unique approach when it comes to proving how data is stored. Filecoin uses Proof of Replication - a proprietary Proof of Storage mechanism that first stores data on storage nodes and then seals the data in a sector. The sealing process allows two replicated pieces of the same data to prove that they are unique to each other, ensuring that the correct number of copies are stored on the network (hence "proof of replication").
Crust breaks a piece of data into many small pieces, which are hashed into a Merkle tree. By comparing the hash result of a single piece of data stored on a physical storage device with the expected Merkle tree hash value, Crust can verify that the file was stored correctly. This is similar to Sia's approach, except that Crust stores the entire file on each node, while Sia stores erasure-coded fragments. Crust can store an entire file on a single node and still achieve privacy through the use of the node's Trusted Execution Environment (TEE), a sealed hardware component that is inaccessible even to the hardware owner. Crust refers to this proof-of-storage algorithm as "meaningful proof-of-work," and meaningfulness means that new hashes are only calculated when changes are made to stored data, reducing meaningless operations. Both Crust and Sia store the Merkle root hash on the blockchain as a source of truth for verifying data integrity.
Storj uses data audits to check that data has been stored correctly. Data auditing is similar to how Crust and Sia use Merkle trees to verify pieces of data. On Storj, once enough nodes return their audit results, the network can determine which nodes are faulty based on the majority response, rather than comparing to the blockchain's source of truth. This mechanism in Storj is intentional because the developers believe that reducing network-wide coordination through the blockchain can improve performance in terms of speed (no need to wait for consensus) and bandwidth usage (no need for the entire network to periodically communicate with the blockchain).
Arweave uses a cryptographic proof-of-work puzzle to determine whether a file has been stored. In this mechanism, for nodes to be able to mine the next block, they need to prove that they have access to the previous block and another random block in the network's block history. Because uploaded data in Arweave is stored directly in blocks, it is proven that the storage provider did save the file correctly by proving access to a previous block.
Finally, Merkle trees are also used on Swarm, with the difference that Merkle trees are not used to determine file locations, but instead data blocks are stored directly in the Merkle tree. When storing data on a swarm, the root hash of the tree (which is also the address where the data is stored) proves that the file was properly chunked and stored.
Data Availability Over Time
Likewise, each network has a unique method when it comes to determining that data was stored for a certain period of time. In Filecoin, in order to reduce network bandwidth, storage miners need to run the proof-of-replication algorithm continuously for the period of time the data is to be stored. The resulting hash of each time period proves that the storage space has been occupied by the correct data during the specific time period, so it is "proof of time and space".
Crust, Sia, and Storj periodically validate random pieces of data and report the results to their coordination mechanisms — Crust and Sia's blockchains, and Storj's satellite nodes. Arweave ensures consistent availability of data through its proof-of-access mechanism, which requires miners to prove not only that they have access to the last block, but also that they have access to a random historical block. Storing older and rarer blocks is an incentive because it increases the likelihood that a miner will win the proof-of-work puzzle that is a prerequisite for accessing a particular block.
Swarm, on the other hand, runs regular sweepstakes that reward nodes for holding less popular data over time, while also running a proof-of-ownership algorithm for data that nodes commit to storing for a longer period of time.
Filecoin, Sia, and Crust require nodes to deposit collateral to become storage nodes, while Swarm only requires it for long-term storage requests. Storj does not require upfront collateral, but Storj will withhold part of the storage revenue from miners. Finally, all networks pay nodes periodically for the period of time they can provably store data.
storage price discovery
To determine storage prices, Filecoin and Sia use storage markets, where storage providers set their asking prices, storage users set the prices they are willing to pay, and a few other settings. The storage marketplace then connects users with storage providers that meet their requirements. Storj takes a similar approach, with the main difference that there is no single network-wide marketplace that connects all nodes on the network. Instead, each satellite has its own set of storage nodes that it interacts with.
In the end, Crust, Arweave, and Swarm all let the protocol determine storage prices. Crust and Swarm can be configured in certain ways based on the user's file storage requirements, while files on Arweave are permanently stored.
persistent data redundancy
Over time, nodes will leave these open public networks, and when nodes disappear, so will the data they store. Therefore, the network must actively maintain some degree of redundancy in the system. Sia and Storj recreate missing fragments by collecting a subset of fragments, reconstructing the underlying data, and then re-encoding the file, achieving redundancy by supplementing lost erasure-coded fragments. In Sia, users must periodically log in to the Sia client to replenish shards, because only the client can distinguish which data shards belong to which data and user. On Storj, however, the Satellite is always online and runs data audits periodically to supplement data fragments.
Arweave's Proof-of-Access algorithm ensures that data is always replicated regularly across the network, whereas on Swarm, data is replicated to nodes that are close to each other. On Filecoin, if data disappears over time and the remaining file fragments fall below a certain threshold, storage orders are reintroduced into the storage market, allowing another storage miner to take over the storage order. Crust's replenishment mechanism is currently under development.
Incentive Data Transfer
image description
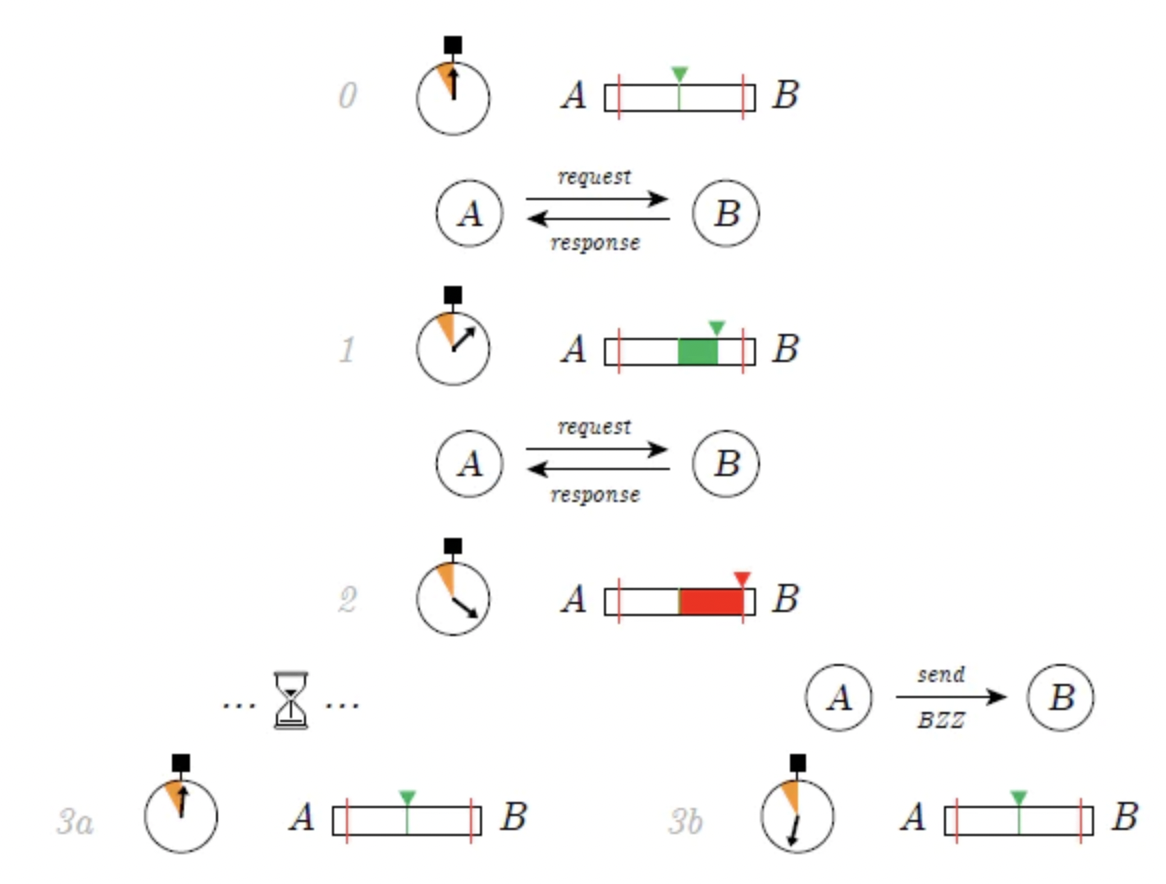
Figure 13: Swarm Accounting Protocol (SWAP), Source: Swarm Whitepaper
token economy
token economy
image description
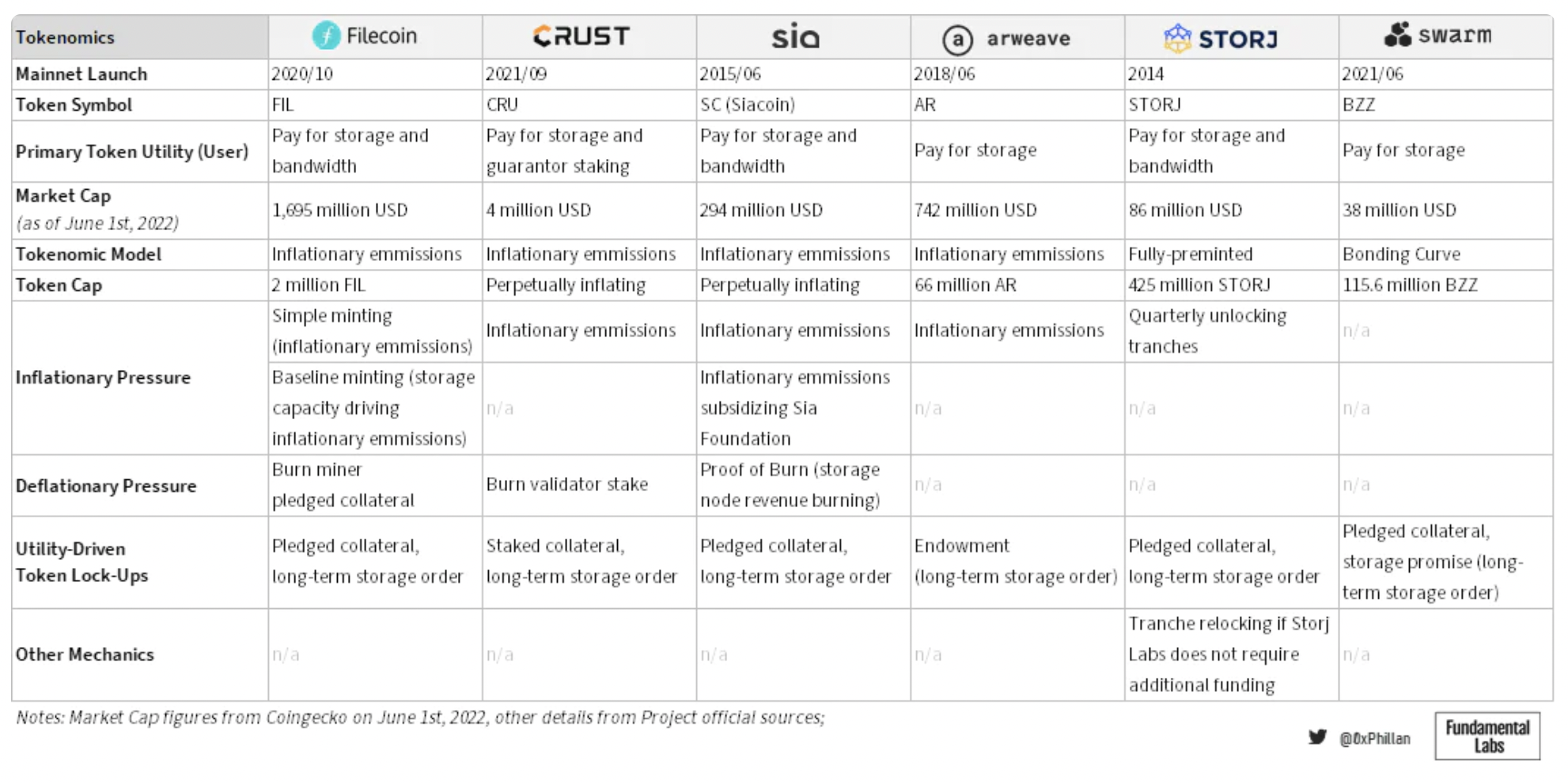
Figure 14: Audited tokenomic design decisions for storage networks.
Which one is the best network?
It cannot be said that one network is objectively better than the other. There are countless trade-offs when designing a decentralized storage network. While Arweave is great for storing data permanently, Arweave is not necessarily suitable for migrating Web2.0 industry players to Web3.0 - not all data needs to be kept forever. However, a strong subfield of data does require permanence: NFTs and dApps.
Ultimately, design decisions will be based on the purpose of the network.
The following is a summary profile of various storage networks, which compare with each other on a set of scales defined below. The scales used reflect the comparative dimensions of these networks, but it should be noted that approaches to overcoming the challenges of decentralized storage are in many cases not better or worse, but simply reflect design decisions.
Storage parameter flexibility: the degree to which the user controls the storage parameters of the file
Storage Persistence: To what extent file storage can be theoretically persistent (i.e. without intervention) over the network
Redundancy Persistence: The ability of the network to maintain data redundancy through replenishment or repair
Data Transfer Incentives: The extent to which the network ensures that nodes transfer data generously
Universality of storage tracking: the degree of consensus among nodes on where data is stored
Assured Data Accessibility: The ability of the network to ensure that a single participant in the storage process cannot remove access to files on the network
Higher scores indicate greater competence in each of the above items.
image description

Figure 15: Filecoin summary overview
Crust's token economics ensure hyper-redundancy and fast retrieval, making it suitable for high-traffic dApps and suitable for fast retrieval of data for popular NFTs.
image description
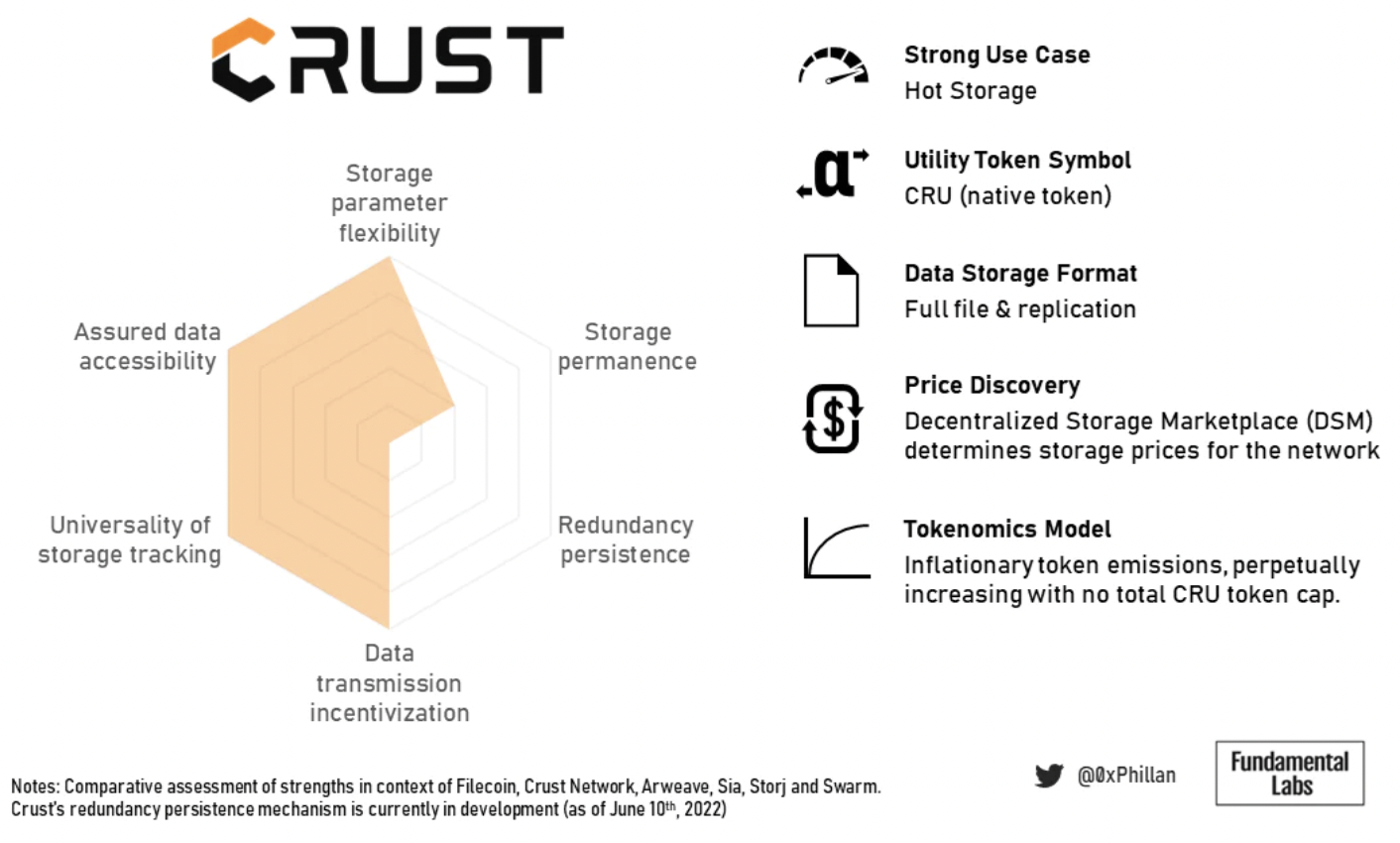
Figure 16: Crust Summary Overview
image description
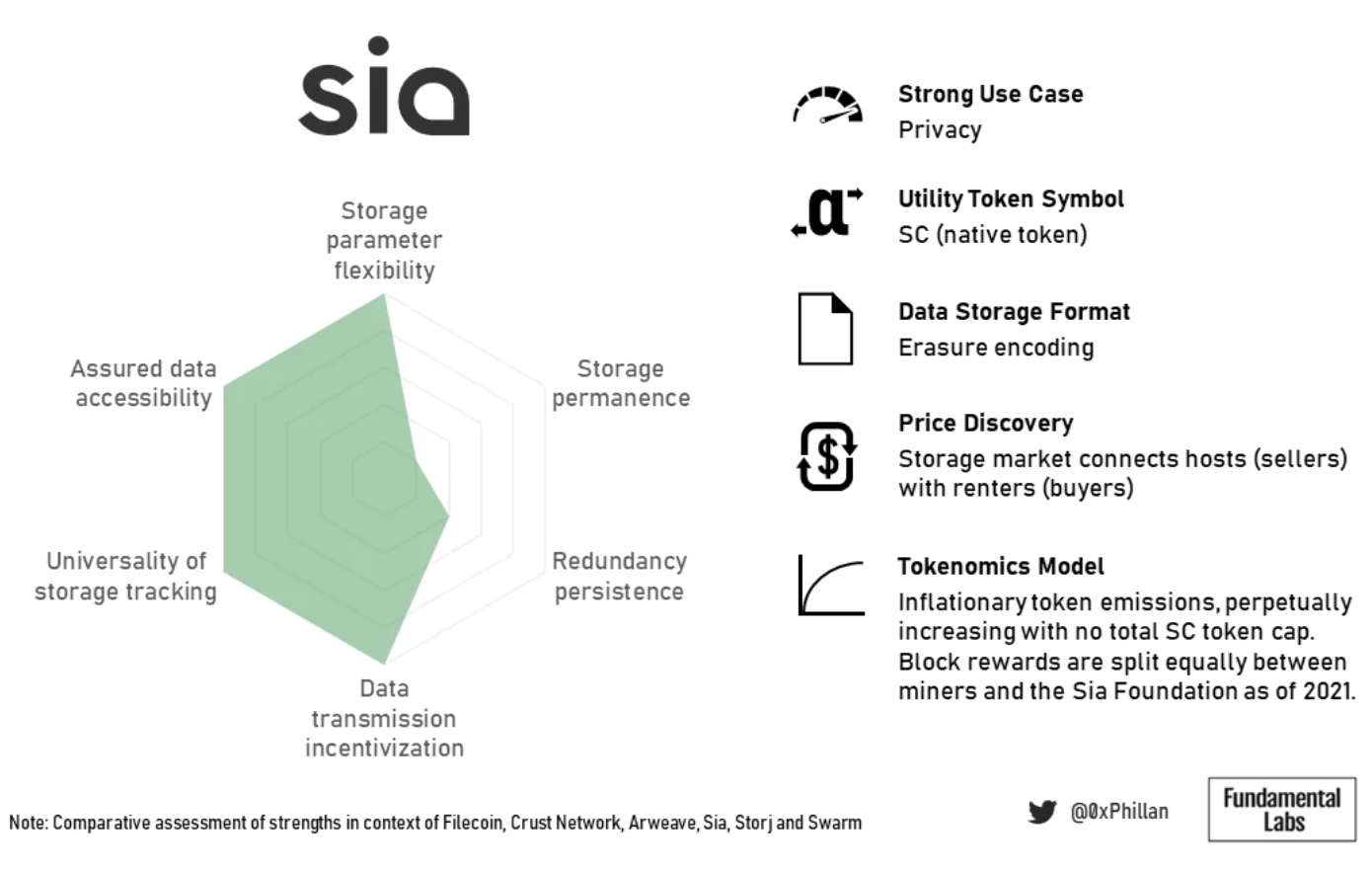
Figure 17: Sia Summary Overview
image description
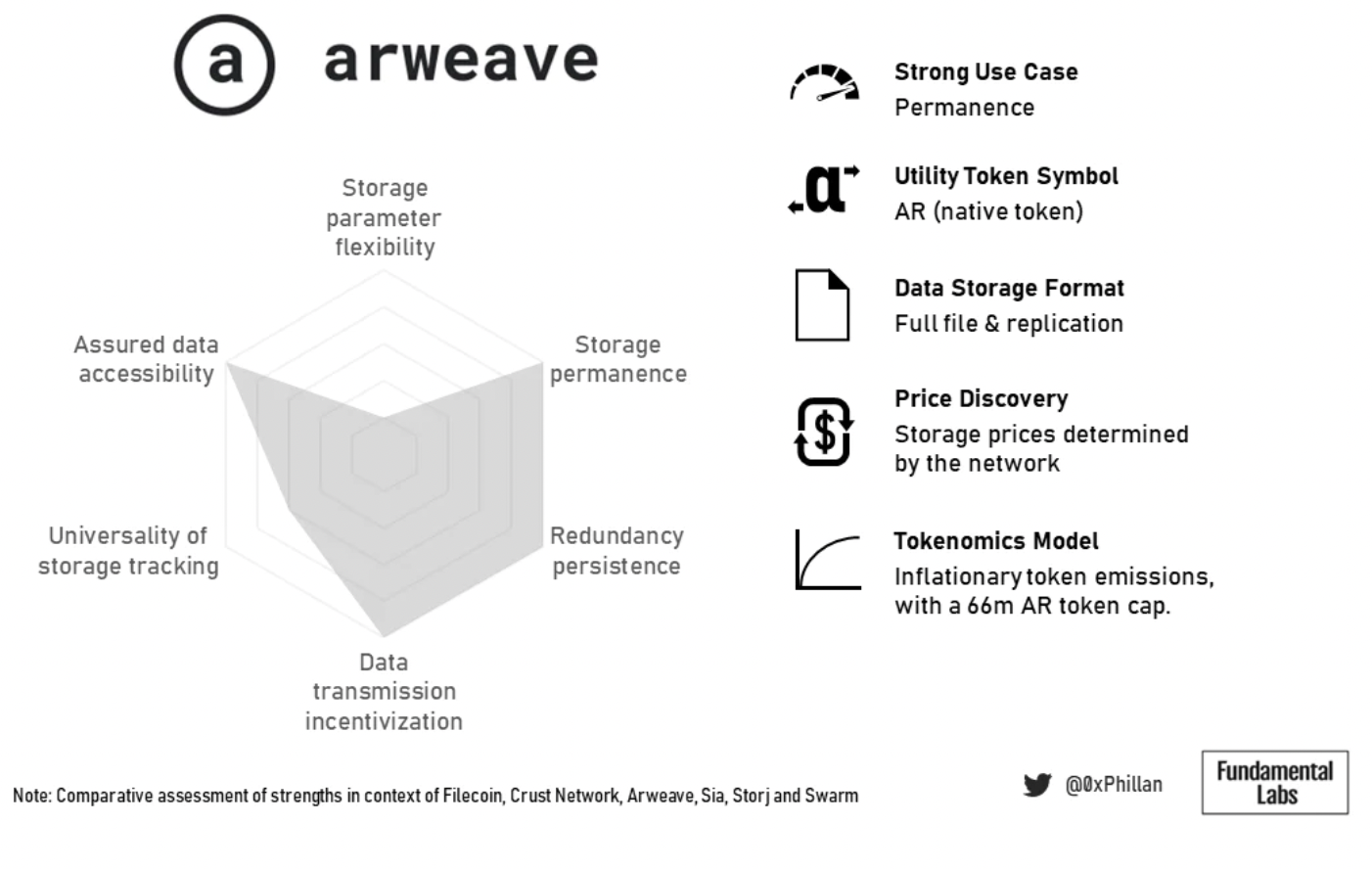
Figure 18: Summary overview of Arweave
image description
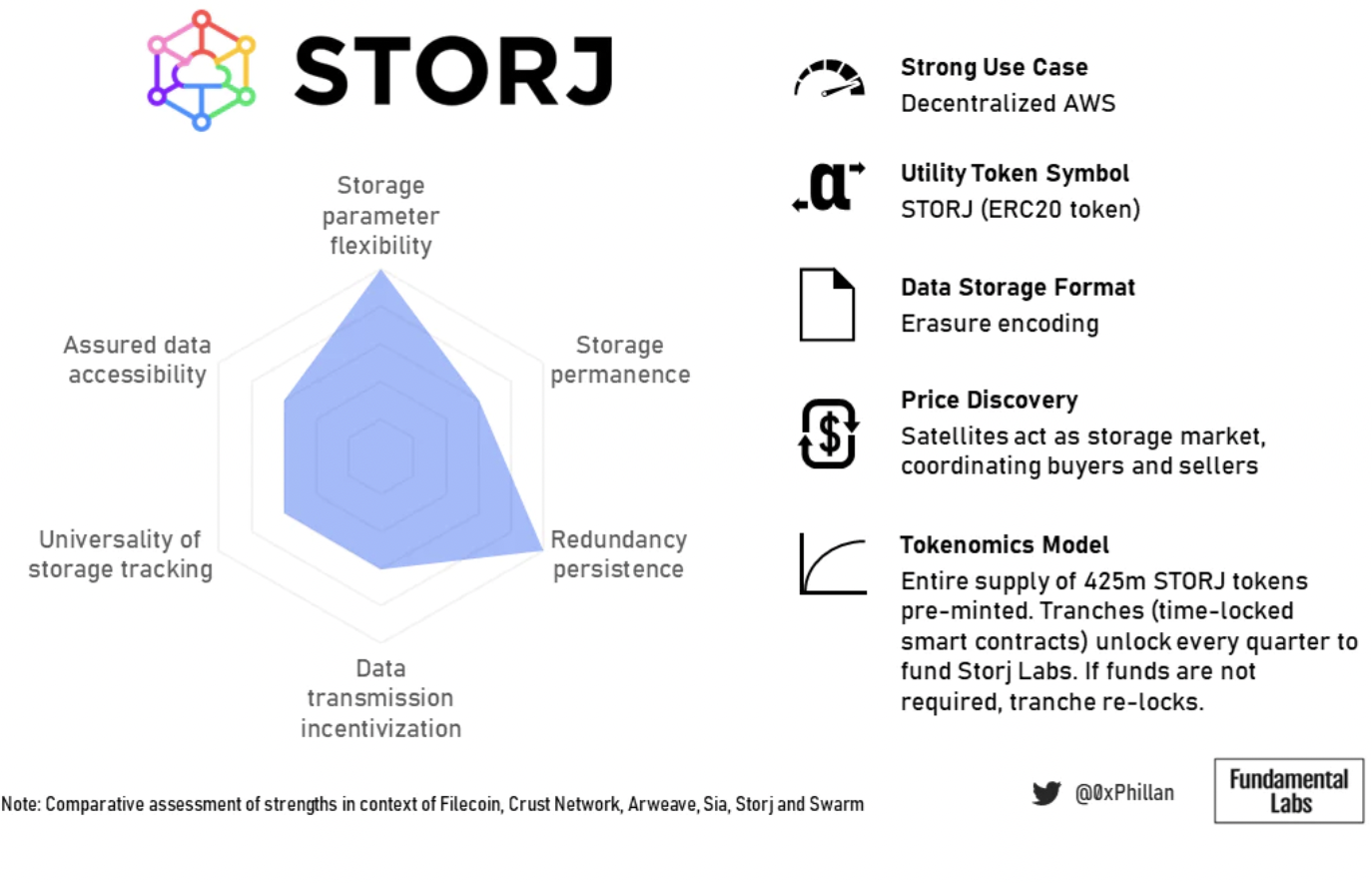
Figure 19: Storj Summary Overview
image description
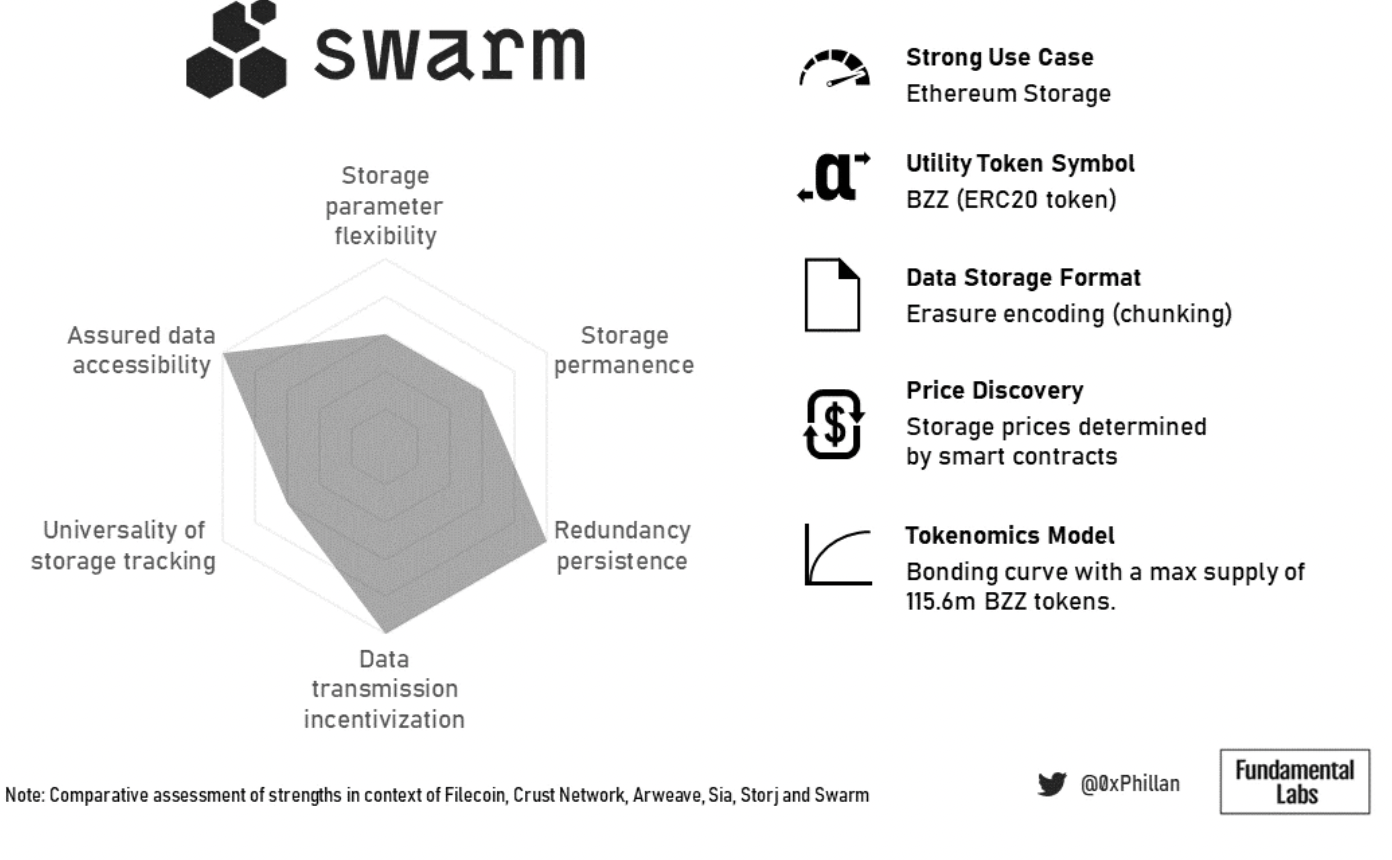
Figure 20: Swarm summary overview
image description

Figure 21: Summary of strong use cases for reviewed storage networks
In the end, the purpose of the network and the specific use case it is trying to optimize will dictate various design decisions.
next chapter
Going back to the Web3 infrastructure pillars (consensus, storage, compute), we see that the decentralized storage space has a handful of strong players who have positioned themselves in the market for specific use cases. This doesn't rule out new networks optimizing existing solutions or capturing new niches, but it does raise the question: what's next?
The answer is: computing. The next frontier towards a truly decentralized internet is decentralized computing. Currently, only a handful of solutions are able to bring to market trustless, decentralized computing solutions that can power complex dApps at a fraction of the cost of executing smart contracts on the blockchain. Costs perform more complex calculations.
Internet Computer (ICP) and Holochain (HOLO) are networks with a strong presence in the decentralized computing market at the time of writing. Still, the computing space is not as crowded as the consensus and storage spaces. Therefore, sooner or later a strong competitor will enter the market and position itself accordingly. Stratos (STOS) is one such competitor. Stratos offers a unique network design through its decentralized data grid technology.
end
end
Thank you for reading this research article on decentralized storage. If you like research aimed at uncovering the fundamental building blocks of our collective Web3 future, consider following @FundamentalLabs on Twitter.
If I'm missing any valuable concepts or other information? Connect with me on Twitter @0xPhillan so we can solidify this research together.
The full work is available atArweave、Crust Networkobtained on
Original link